Creating a K Nearest Neighbors Classifer from scratch
Welcome to the 16th part of our Machine Learning with Python tutorial series, where we're currently covering classification with the K Nearest Neighbors algorithm. In the previous tutorial, we covered Euclidean Distance, and now we're going to be setting up our own simple example in pure Python code.
To start, let's make the following imports and set a style for matplotlib:
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import style
import warnings
from math import sqrt
from collections import Counter
style.use('fivethirtyeight')
We're going to use warnings to avoid using a lower K value than we have groups, math for the square root functionality, at least initially (since I will show a more efficient method), and then Counter from collections to get the most popular votes.
Next, we create some data:
dataset = {'k':[[1,2],[2,3],[3,1]], 'r':[[6,5],[7,7],[8,6]]}
new_features = [5,7]
The dataset is just a Python dictionary with the keys being the color of the points (think of these as the class), and then the datapoints that are attributed with this class. If you recall our breast cancer dataset, the classes were numbers, and often times will be numbers to work with scikit-learn. For example, "benign" was translated to being given an arbitrary number of "2" and malignant was given the number of "4" in the dataset, rather than a string. This is mainly because Scikit-Learn simply required use to use numbers, but you do not inherently actually need to use numbers for your classes with a K Nearest Neighbors classifier. Next, we just specify a simple data set, 5,7 to be data we want to test. We can create a quick graph by doing:
[[plt.scatter(ii[0],ii[1],s=100,color=i) for ii in dataset[i]] for i in dataset] plt.scatter(new_features[0], new_features[1], s=100) plt.show()
Giving us:
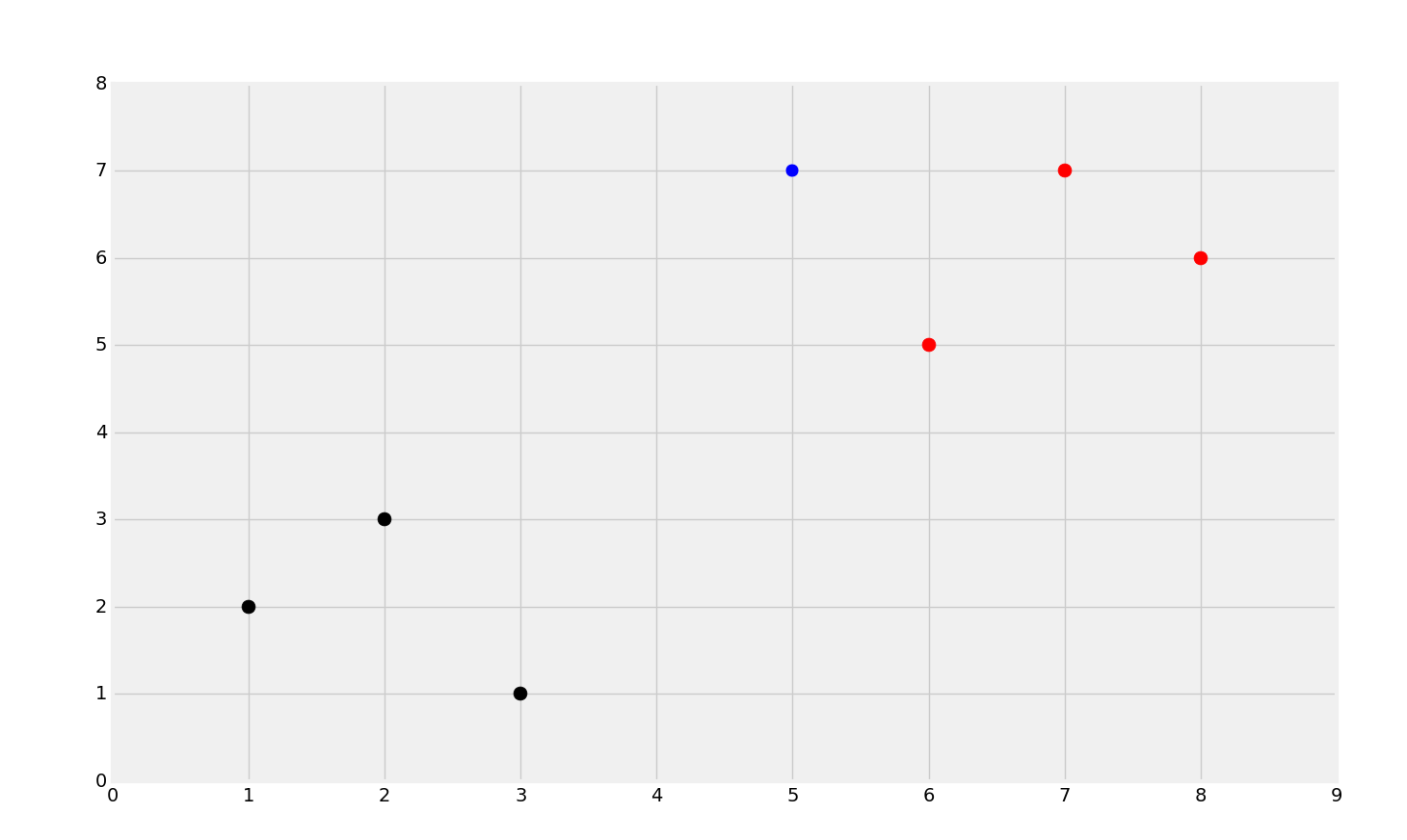
The line that is [[plt.scatter(ii[0],ii[1],s=100,color=i) for ii in dataset[i]] for i in dataset] is the same as:
for i in dataset:
for ii in dataset[i]:
plt.scatter(ii[0],ii[1],s=100,color=i)
You can see there are obvious groups of red and black, and then we have the blue dot. The blue dot is the new_features, which we're going to attempt to classify.
We have our data, now we want to create some sort of function that will actually classify the data:
def k_nearest_neighbors(data, predict, k=3):
return vote_result
There's a skeleton of what we expect to have here to start. We want a function that will take in data to train against, new data to predict with, and a value for K, which we'll just set as defaulting to 3.
Next, we'll begin populating the function, first with a simple warning:
def k_nearest_neighbors(data, predict, k=3):
if len(data) >= k:
warnings.warn('K is set to a value less than total voting groups!')
return vote_result
We have this warning to warn the user if they attempt to use the K Nearest Neighbors function to vote where the nearest neighbors selected is less than or equal to the number of groups that can vote (since allowing for this could still give us a tie).
Now, how do we find the closest three points? Is there some magical formula that finds these? Unforunately not. If there ever was one, that would be massive. Why? The main downfall of K Nearest Neighbors is that we have to compare the data in question to all of the points from the dataset before we can know what the closest three points are. As such, K Nearest Neighbors performs slower and slower the more data you have. We'll get there in the end, but consider if there is a way to speed up the process as we go.
-
Practical Machine Learning Tutorial with Python Introduction
-
Regression - Intro and Data
-
Regression - Features and Labels
-
Regression - Training and Testing
-
Regression - Forecasting and Predicting
-
Pickling and Scaling
-
Regression - Theory and how it works
-
Regression - How to program the Best Fit Slope
-
Regression - How to program the Best Fit Line
-
Regression - R Squared and Coefficient of Determination Theory
-
Regression - How to Program R Squared
-
Creating Sample Data for Testing
-
Classification Intro with K Nearest Neighbors
-
Applying K Nearest Neighbors to Data
-
Euclidean Distance theory
-
Creating a K Nearest Neighbors Classifer from scratch
-
Creating a K Nearest Neighbors Classifer from scratch part 2
-
Testing our K Nearest Neighbors classifier
-
Final thoughts on K Nearest Neighbors
-
Support Vector Machine introduction
-
Vector Basics
-
Support Vector Assertions
-
Support Vector Machine Fundamentals
-
Constraint Optimization with Support Vector Machine
-
Beginning SVM from Scratch in Python
-
Support Vector Machine Optimization in Python
-
Support Vector Machine Optimization in Python part 2
-
Visualization and Predicting with our Custom SVM
-
Kernels Introduction
-
Why Kernels
-
Soft Margin Support Vector Machine
-
Kernels, Soft Margin SVM, and Quadratic Programming with Python and CVXOPT
-
Support Vector Machine Parameters
-
Machine Learning - Clustering Introduction
-
Handling Non-Numerical Data for Machine Learning
-
K-Means with Titanic Dataset
-
K-Means from Scratch in Python
-
Finishing K-Means from Scratch in Python
-
Hierarchical Clustering with Mean Shift Introduction
-
Mean Shift applied to Titanic Dataset
-
Mean Shift algorithm from scratch in Python
-
Dynamically Weighted Bandwidth for Mean Shift
-
Introduction to Neural Networks
-
Installing TensorFlow for Deep Learning - OPTIONAL
-
Introduction to Deep Learning with TensorFlow
-
Deep Learning with TensorFlow - Creating the Neural Network Model
-
Deep Learning with TensorFlow - How the Network will run
-
Deep Learning with our own Data
-
Simple Preprocessing Language Data for Deep Learning
-
Training and Testing on our Data for Deep Learning
-
10K samples compared to 1.6 million samples with Deep Learning
-
How to use CUDA and the GPU Version of Tensorflow for Deep Learning
-
Recurrent Neural Network (RNN) basics and the Long Short Term Memory (LSTM) cell
-
RNN w/ LSTM cell example in TensorFlow and Python
-
Convolutional Neural Network (CNN) basics
-
Convolutional Neural Network CNN with TensorFlow tutorial
-
TFLearn - High Level Abstraction Layer for TensorFlow Tutorial
-
Using a 3D Convolutional Neural Network on medical imaging data (CT Scans) for Kaggle
-
Classifying Cats vs Dogs with a Convolutional Neural Network on Kaggle
-
Using a neural network to solve OpenAI's CartPole balancing environment
