Intro to Machine Learning with Scikit Learn and Python
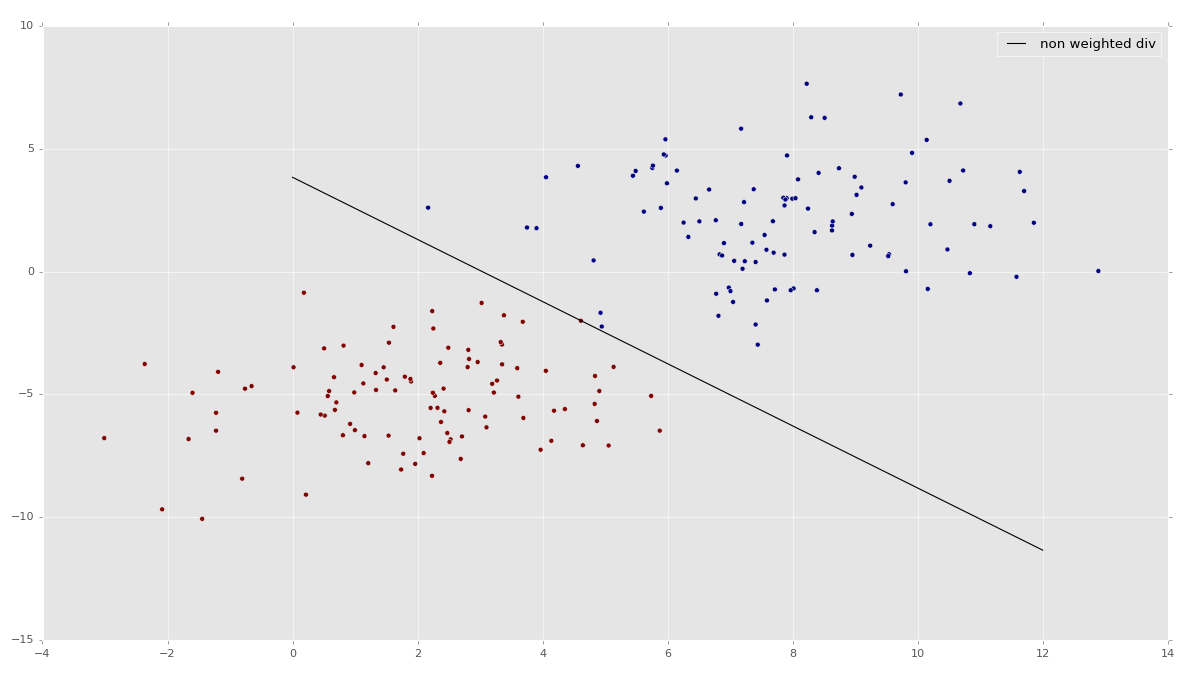
While a lot of people like to make it sound really complex, machine learning is quite simple at its core and can be best envisioned as machine classification. Machine learning shines when the number of dimensions exceeds what we can graphically represent, but here's a nice 2D representation of machine learning with two features:
 The above image is taken from part 11 of this series, where we show an extremely basic example of how a Support Vector Machine (SVM) works. This particular example and the specific estimator that we will be using is linear SVC. If that means nothing to you now, that is perfectly okay.
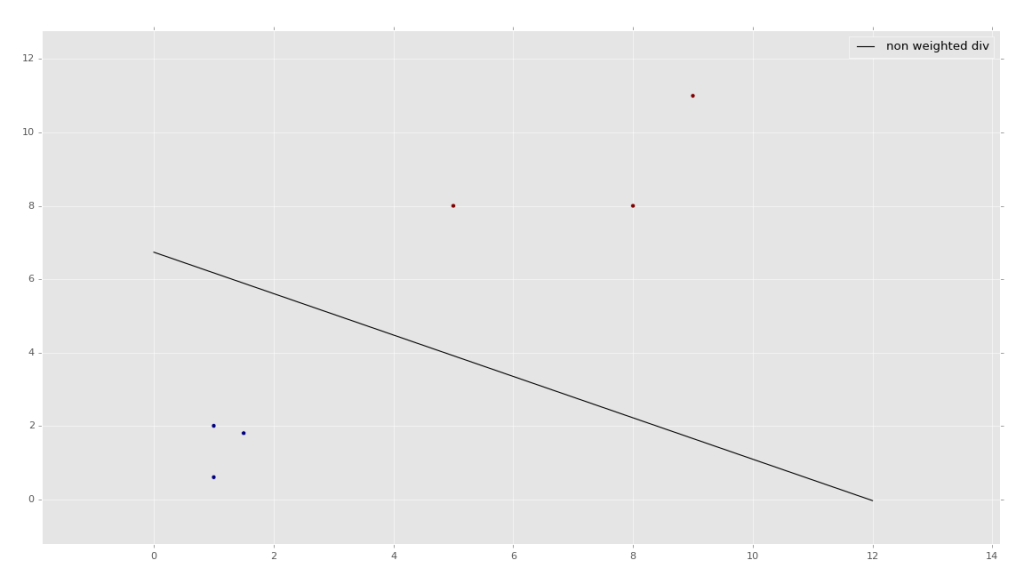
The above image is taken by feeding through data sets of x,y coordinates like:
The above image is taken from part 11 of this series, where we show an extremely basic example of how a Support Vector Machine (SVM) works. This particular example and the specific estimator that we will be using is linear SVC. If that means nothing to you now, that is perfectly okay.
The above image is taken by feeding through data sets of x,y coordinates like:
[1,2],
[5,8],
[1.5,1.8],
[8,8],
[1,0.6],
[9,11]
As you can see, this data set has some larger pairs, and some smaller pairs. What an SVM is going to do is help you find the perfect dividing line between the data. We can then take it a step further, and ask the SVM to predict which "group" a coordinate like [0.8,0.92] would belong to.
With features (think of these as dimensions) as 2D or 3D, it is really quite simple to visualize and for us humans to just look at the graph and do some basic clustering. Machine learning, however, can be used to analyze, say, 100 features (100 dimensions). Try that yourself with 5 billion samples.
This series is concerned with machine learning in a hands-on and practical manner, using the Python programming language and the Scikit-learn module (sklearn).
Our example used here is to analyze fundamental characteristics of publicly-traded companies (stocks), comparing these fundamentals to the stock's market value performance over time. Our goal is to see if we can use machine learning to identify good stocks with solid fundamentals that matter so we can invest in them.
I will try to cover more machine learning examples in the future, as each machine learning algorithm is fairly specific to the "type" of problem you might have. A Support Vector Machine (SVM) is great for some tasks, but very poor for others. There are many other machine learning algorithms to learn about, and there is a lot more to learn about machine learning in general. We're going to be taken only a small slice of the pie per machine learning algorithm that we use.
Machine learning, for the most part, is not actual learning at all, though a lot of people in the media generally fear-monger with that as the premise.
With machine learning, we can perform a lot of amazing tasks and give the appearance, or probably better put: "the illusion" of intelligence, but it's not really intelligence as we know it. The real question, however, is if that matters in the end? If the end-result is the same, and achieved in a far more efficient manner, then what does it matter how the conclusion was reached?
There are many applications where this form of computing is superior to human intelligence. Properly weighing and analyzing all aspects is simply done better with less bias, and far quicker, by computers.
There are two main categories of machine learning:
Supervised learning
Unsupervised learning.
Within supervised learning, we have classification and regression. Remember earlier when I said machine learning is really just machine classification? It still is, but there's also a specific form of machine learning called classification.
So, supervised learning is where we, the scientist, supervise and sometimes sort of guide the learning process. We might say what some of the data is, and leave some to question.
Within supervised learning, we have classification, which is where we already have the classifications done. An example here would be the image recognition tutorial we did, where you have a set of numbers, and you have an unknown that you want to fit into one of your pre-defined categories.
Then we have regression, still under supervised learning, which is maybe better called induction or something like that, where we have certain known variables of the data in question, and then, using past sample or historical data, we can make predictions on the unknown.
An example here would be what Facebook does to you when it guesses where you live. Given your network and the people you have the closest ties to and communicate with, and where they are from, Facebook can then guess that you too are from that location.
Another example would be if we sample a million people, then find an unknown person who has blonde hair and pale skin. We're curious what color eyes that they have. Our regression algorithm will probably suggest our new person has blue or grey eyes, based on the previous samples.
Now, immediately red flags should probably go off here. For you philosophy majors out there, you knew there was a problem immediately when we used inductive reasoning. For the rest of you, the problem is we're making predictions here, using the weaker form of reasoning.
All that said, humans have owed quite a bit of their evolution to their ability to do inductive reasoning. It is not all bad, but people do like to use inductive reasoning and regression analysis for things like trading stocks. The problem is this reasoning follows history and makes predictions to the future. As we know and hear many times over and over, history is not a representation of future.
I do not want to spend too much time here, but I would like to lastly point out, with induction, computers are better at it than humans. When it comes to inductive reasoning, humans have the tendency to miss-judge and incorrectly weigh various attributes. They generally have a lot more bias, and other statistical flaws that particularly plague inductive reasoning. Computers do not have these issues, and they can perform this reasoning on a far larger data set at an astronomically faster pace than us.
Unsupervised learning is where we create the learning algorithm, then we just throw a ton of data at the computer and we let the computer make sense of it.
The basics of unsupervised learning is to just throw a massive data set at the machine, and the machine, you guessed it, classifies, or groups, the data. this is why the terms can be confusing. Just remember that all machine learning is machine classification, and the specific version of machine learning called classification is where we're just pre-defining categories, forcing the machine to choose one.
The last major terms I would like to have us cover here before we get our feet wet are testing and training
When we "train" the machine, this is where we give data which is pre-classified. So again, with the image recognition series, we trained our machine by giving it examples of 0s through 9s.
When we test this algo, we use new, unclassified data to the machine, but we know the proper classification. Generally, you feed the data through to test it, then you run the correct answers through the machine and see how many the machine got right and wrong.
As you may soon find, actually acquiring the data necessary for training and testing is the most challenging part. For me and Sentdex.com, which does sentiment analysis of text, I was able to use movie and product reviews scraped offline as my training and testing sets. The reviews come with rankings, so I could train and test the machine on massive data-sets that were personally ranked by the reviewer themselves.
I made this picture long ago, but I find it still applies to machine learning:

While I think machine learning is actually more complicated than that, most people are likely to read about machine learning and think it is incredibly complicated both in programming and mathematically, thus being scared off.
While machine learning algorithms are actually incredibly long and complex, you will almost never need to write your own, except just for fun or just to see if you can.
In almost all production cases, you wouldn't want to write your own, nor should you. You will want to use a peer-reviewed, highly efficient, and highly tested algorithm. For most major cases, there will be a very effective algorithm available for you. Because of this, it's actually not necessary for you to learn about all of the inner workings of machine learning to be successful with it.
You can think of this much like how you probably treat your car, your computer, or your cell phone. You can get a lot of utility out of these things, yet you probably actually know very little about all of the intricacies of them.
Machine learning is the same way. It's best to understand some of the major parameters, like "learning rate," as well as what machine learning is actually doing for you, that way you can figure how how best to apply machine learning to a problem. This is why I find visualizing some examples before moving into impossible dimensions is a great idea.
Of course, you may find that you're curious about the inner-workings, and I would encourage you to feed your curiosity. The algorithms are truly fascinating, and it will certainly improve your efficacy the more you understand the algorithms that you intend to employ.
The focus of this course is to actually apply a machine learning algorithm to a problem. If that sounds like something you'd like to do, head to the next tutorial.
There exists 2 quiz/question(s) for this tutorial. for access to these, video downloads, and no ads.
-
Intro to Machine Learning with Scikit Learn and Python
-
Simple Support Vector Machine (SVM) example with character recognition
-
Our Method and where we will be getting our Data
-
Parsing data
-
More Parsing
-
Structuring data with Pandas
-
Getting more data and meshing data sets
-
Labeling of data part 1
-
Labeling data part 2
-
Finally finishing up the labeling
-
Linear SVC Machine learning SVM example with Python
-
Getting more features from our data
-
Linear SVC machine learning and testing our data
-
Scaling, Normalizing, and machine learning with many features
-
Shuffling our data to solve a learning issue
-
Using Quandl for more data
-
Improving our Analysis with a more accurate measure of performance in relation to fundamentals
-
Learning and Testing our Machine learning algorithm
-
More testing, this time including N/A data
-
Back-testing the strategy
-
Pulling current data from Yahoo
-
Building our New Data-set
-
Searching for investment suggestions
-
Raising investment requirement standards
-
Testing raised standards
-
Streamlining the changing of standards
