Scheduling a function on Quantopian - Python Programming for Finance p.15
Hello and welcome to part 15 of the Python for Finance tutorial series, using Quantopian and Zipline. In this tutorial, we're going to cover the schedule_function.
In our case, we're really only meaning to actually trade once a day, not multiple times a day. Besides simply trading, another common practice to use "rebalance" a portfolio in some sort timely manner. Maybe weekly, maybe daily, maybe monthly you want to properly balance, or "diversify" your portfolio. This scheduling functionality lets you do just that! To schedule functions, you call the schedule_function function from within the initialize method.
def initialize(context):
context.aapl = sid(24)
schedule_function(ma_crossover_handling, date_rules.every_day(), time_rules.market_open(hours=1))
Here, we're saying that we want to have a scheduled function that runs every_day, 1 hour after market_open. As usual, there are many options here. You can do "x" hours before market close (still using positive values). For example if you wanted to do this 1 hour before market_close, it would be time_rules.market_close(hours=1). You can also schedule in minutes, like: time_rules.market_close(hours=0, minutes=1), which means to run this function 1 minute before the markets close.
Now, what we want to do is take the following code from the handle_data function:
hist = data.history(context.aapl,'price', 50, '1d')
sma_50 = hist.mean()
sma_20 = hist[-20:].mean()
open_orders = get_open_orders()
if sma_20 > sma_50:
if context.aapl not in open_orders:
order_target_percent(context.aapl, 1.0)
elif sma_20 < sma_50:
if context.aapl not in open_orders:
order_target_percent(context.aapl, -1.0)
...cut it and place it under a new function ma_crossover_handling
def ma_crossover_handling(context,data):
hist = data.history(context.aapl,'price', 50, '1d')
sma_50 = hist.mean()
sma_20 = hist[-20:].mean()
open_orders = get_open_orders()
if sma_20 > sma_50:
if context.aapl not in open_orders:
order_target_percent(context.aapl, 1.0)
elif sma_20 < sma_50:
if context.aapl not in open_orders:
order_target_percent(context.aapl, -1.0)
Note that we're passing both context and data here. Now, run the full back-test, and you should notice that this runs *much* faster than before. This is because we're not actually re-calculating those moving averages every minute, we're just doing it daily now. This is saving us a ton of processing.
Notice, however, that some of our transaction bars are showing that we're buying or selling almost $2 million worth of shares, when our capital is supposed to be $1 million, and we're not doing well enough to have doubled it.
The shorting is causing this. When we short a company on Quantopian, we've got negative shares. For example, let's say we short 100 shares of Apple. This means we have a -100 share position in Apple. Then consider we want to change our position to be holding 100 shares of Apple. We actually need to buy 100 shares to just be at 0 shares, then another hundred shares to be at +100. The same is true to go from +100 to -100. This is why we have those seemingly double-sized trades, without leverage. So we're about -7% by buying (going long), and shorting Apple, depending on the moving average crossovers. What might happen if we just buy and sell instead of buying and shorting?
def initialize(context):
context.aapl = sid(24)
schedule_function(ma_crossover_handling, date_rules.every_day(), time_rules.market_open(hours=1))
def handle_data(context,data):
record(leverage=context.account.leverage)
def ma_crossover_handling(context,data):
hist = data.history(context.aapl,'price', 50, '1d')
sma_50 = hist.mean()
sma_20 = hist[-20:].mean()
open_orders = get_open_orders()
if sma_20 > sma_50:
if context.aapl not in open_orders:
order_target_percent(context.aapl, 1.0)
elif sma_20 < sma_50:
if context.aapl not in open_orders:
order_target_percent(context.aapl, 0.0)
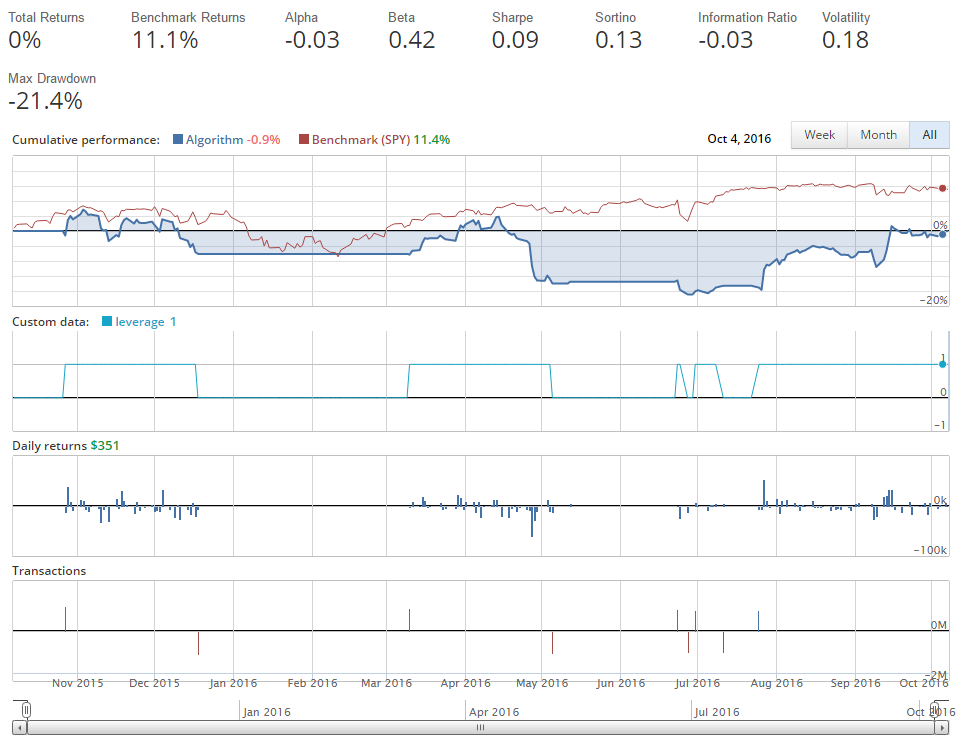
We've basically run in place. Usually, around this time, people start thinking about adjusting the moving averages. Maybe 10 and 50. Or maybe 2 and 50!
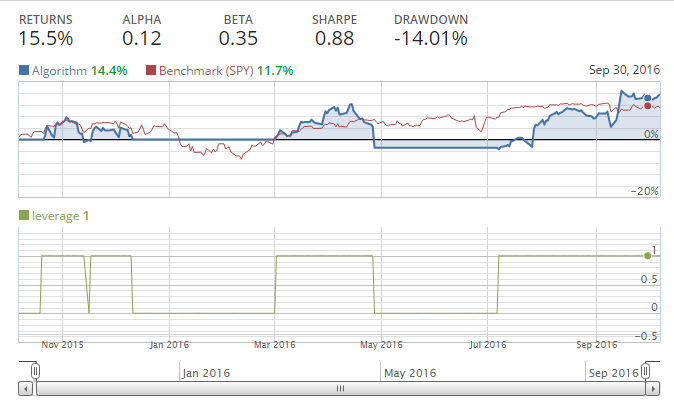
Yes, 2 and 50 are the magical numbers! We beat the market. The problem is, we have no real reason for these random numbers, other than that we specifically kept running our back test until we had something successful. This is a form of data-snooping, and is a common pitfall, and something you want to avoid. Picking specific moving averages, for examples, to "best fit" the historical data is likely to cause future problems, since those numbers were meant for historical data, and not new, unforeseen data. Consider how much Apple has changed as well over the years as a company. It went from being a computer company, to a who really knows company, to being a computer-ish company, to being an MP3 player company, to a phone and computer company. The stock's behavior is likely to continue changing into the future, as the company itself also changes.
Instead, we need to look into our strategy, and realize a moving average crossover strategy is just not good. We need something else, and we need something that makes sense as a strategy, and then we use a back test to either validate it, or not. We do not want to find ourselves constantly tweaking our strategy a bit and curiously back testing to see if we can find some magic numbers. This is unlikely to pan out well in the future for us.
-
Intro and Getting Stock Price Data - Python Programming for Finance p.1
-
Handling Data and Graphing - Python Programming for Finance p.2
-
Basic stock data Manipulation - Python Programming for Finance p.3
-
More stock manipulations - Python Programming for Finance p.4
-
Automating getting the S&P 500 list - Python Programming for Finance p.5
-
Getting all company pricing data in the S&P 500 - Python Programming for Finance p.6
-
Combining all S&P 500 company prices into one DataFrame - Python Programming for Finance p.7
-
Creating massive S&P 500 company correlation table for Relationships - Python Programming for Finance p.8
-
Preprocessing data to prepare for Machine Learning with stock data - Python Programming for Finance p.9
-
Creating targets for machine learning labels - Python Programming for Finance p.10 and 11
-
Machine learning against S&P 500 company prices - Python Programming for Finance p.12
-
Testing trading strategies with Quantopian Introduction - Python Programming for Finance p.13
-
Placing a trade order with Quantopian - Python Programming for Finance p.14
-
Scheduling a function on Quantopian - Python Programming for Finance p.15
-
Quantopian Research Introduction - Python Programming for Finance p.16
-
Quantopian Pipeline - Python Programming for Finance p.17
-
Alphalens on Quantopian - Python Programming for Finance p.18
-
Back testing our Alpha Factor on Quantopian - Python Programming for Finance p.19
-
Analyzing Quantopian strategy back test results with Pyfolio - Python Programming for Finance p.20
-
Strategizing - Python Programming for Finance p.21
-
Finding more Alpha Factors - Python Programming for Finance p.22
-
Combining Alpha Factors - Python Programming for Finance p.23
-
Portfolio Optimization - Python Programming for Finance p.24
-
Zipline Local Installation for backtesting - Python Programming for Finance p.25
-
Zipline backtest visualization - Python Programming for Finance p.26
-
Custom Data with Zipline Local - Python Programming for Finance p.27
-
Custom Markets Trading Calendar with Zipline (Bitcoin/cryptocurrency example) - Python Programming for Finance p.28
