Chunking with NLTK
Now that we know the parts of speech, we can do what is called chunking, and group words into hopefully meaningful chunks. One of the main goals of chunking is to group into what are known as "noun phrases." These are phrases of one or more words that contain a noun, maybe some descriptive words, maybe a verb, and maybe something like an adverb. The idea is to group nouns with the words that are in relation to them.
In order to chunk, we combine the part of speech tags with regular expressions. Mainly from regular expressions, we are going to utilize the following:
+ = match 1 or more ? = match 0 or 1 repetitions. * = match 0 or MORE repetitions . = Any character except a new line
See the tutorial linked above if you need help with regular expressions. The last things to note is that the part of speech tags are denoted with the "<" and ">" and we can also place regular expressions within the tags themselves, so account for things like "all nouns" (<N.*>)
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
tokenized = custom_sent_tokenizer.tokenize(sample_text)
def process_content():
try:
for i in tokenized:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
chunkGram = r"""Chunk: {<RB.?>*<VB.?>*<NNP>+<NN>?}"""
chunkParser = nltk.RegexpParser(chunkGram)
chunked = chunkParser.parse(tagged)
chunked.draw()
except Exception as e:
print(str(e))
process_content()
The result of this is something like:
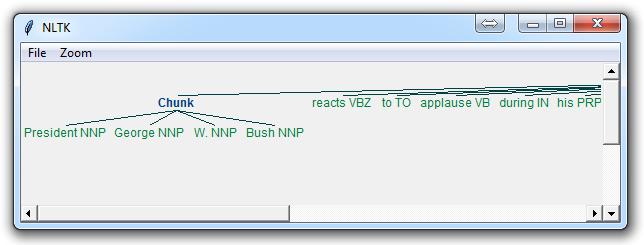
The main line here in question is:
chunkGram = r"""Chunk: {<RB.?>*<VB.?>*<NNP>+<NN>?}"""
This line, broken down:
<RB.?>* = "0 or more of any tense of adverb," followed by:
<VB.?>* = "0 or more of any tense of verb," followed by:
<NNP>+ = "One or more proper nouns," followed by
<NN>? = "zero or one singular noun."
Try playing around with combinations to group various instances until you feel comfortable with chunking.
Not covered in the video, but also a reasonable task is to actually access the chunks specifically. This is something rarely talked about, but can be an essential step depending on what you're doing. Say you print the chunks out, you are going to see output like:
(S
(Chunk PRESIDENT/NNP GEORGE/NNP W./NNP BUSH/NNP)
'S/POS
(Chunk
ADDRESS/NNP
BEFORE/NNP
A/NNP
JOINT/NNP
SESSION/NNP
OF/NNP
THE/NNP
CONGRESS/NNP
ON/NNP
THE/NNP
STATE/NNP
OF/NNP
THE/NNP
UNION/NNP
January/NNP)
31/CD
,/,
2006/CD
THE/DT
(Chunk PRESIDENT/NNP)
:/:
(Chunk Thank/NNP)
you/PRP
all/DT
./.)
Cool, that helps us visually, but what if we want to access this data via our program? Well, what is happening here is our "chunked" variable is an NLTK tree. Each "chunk" and "non chunk" is a "subtree" of the tree. We can reference these by doing something like chunked.subtrees. We can then iterate through these subtrees like so:
for subtree in chunked.subtrees():
print(subtree)
Next, we might be only interested in getting just the chunks, ignoring the rest. We can use the filter parameter in the chunked.subtrees() call.
for subtree in chunked.subtrees(filter=lambda t: t.label() == 'Chunk'):
print(subtree)
Now, we're filtering to only show the subtrees with the label of "Chunk." Keep in mind, this isn't "Chunk" as in the NLTK chunk attribute... this is "Chunk" literally because that's the label we gave it here: chunkGram = r"""Chunk: {<RB.?>*<VB.?>*<NNP>+<NN>?}"""
Had we said instead something like chunkGram = r"""Pythons: {<RB.?>*<VB.?>*<NNP>+<NN>?}""", then we would filter by the label of "Pythons." The result here should be something like:
- (Chunk PRESIDENT/NNP GEORGE/NNP W./NNP BUSH/NNP) (Chunk ADDRESS/NNP BEFORE/NNP A/NNP JOINT/NNP SESSION/NNP OF/NNP THE/NNP CONGRESS/NNP ON/NNP THE/NNP STATE/NNP OF/NNP THE/NNP UNION/NNP January/NNP) (Chunk PRESIDENT/NNP) (Chunk Thank/NNP)
Full code for this would be:
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
tokenized = custom_sent_tokenizer.tokenize(sample_text)
def process_content():
try:
for i in tokenized:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
chunkGram = r"""Chunk: {<RB.?>*<VB.?>*<NNP>+<NN>?}"""
chunkParser = nltk.RegexpParser(chunkGram)
chunked = chunkParser.parse(tagged)
print(chunked)
for subtree in chunked.subtrees(filter=lambda t: t.label() == 'Chunk'):
print(subtree)
chunked.draw()
except Exception as e:
print(str(e))
process_content()
If you get particular enough, you may find that you may be better off if there was a way to chunk everything, except some stuff. This process is what is known as chinking, and that's what we're going to be covering next.
There exists 1 quiz/question(s) for this tutorial. for access to these, video downloads, and no ads.
-
Tokenizing Words and Sentences with NLTK
-
Stop words with NLTK
-
Stemming words with NLTK
-
Part of Speech Tagging with NLTK
-
Chunking with NLTK
-
Chinking with NLTK
-
Named Entity Recognition with NLTK
-
Lemmatizing with NLTK
-
The corpora with NLTK
-
Wordnet with NLTK
-
Text Classification with NLTK
-
Converting words to Features with NLTK
-
Naive Bayes Classifier with NLTK
-
Saving Classifiers with NLTK
-
Scikit-Learn Sklearn with NLTK
-
Combining Algorithms with NLTK
-
Investigating bias with NLTK
-
Improving Training Data for sentiment analysis with NLTK
-
Creating a module for Sentiment Analysis with NLTK
-
Twitter Sentiment Analysis with NLTK
-
Graphing Live Twitter Sentiment Analysis with NLTK with NLTK
-
Named Entity Recognition with Stanford NER Tagger
-
Testing NLTK and Stanford NER Taggers for Accuracy
-
Testing NLTK and Stanford NER Taggers for Speed
-
Using BIO Tags to Create Readable Named Entity Lists
