Chinking with NLTK
You may find that, after a lot of chunking, you have some words in your chunk you still do not want, but you have no idea how to get rid of them by chunking. You may find that chinking is your solution.
Chinking is a lot like chunking, it is basically a way for you to remove a chunk from a chunk. The chunk that you remove from your chunk is your chink.
The code is very similar, you just denote the chink, after the chunk, with }{ instead of the chunk's {}.
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
tokenized = custom_sent_tokenizer.tokenize(sample_text)
def process_content():
try:
for i in tokenized[5:]:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
chunkGram = r"""Chunk: {<.*>+}
}<VB.?|IN|DT|TO>+{"""
chunkParser = nltk.RegexpParser(chunkGram)
chunked = chunkParser.parse(tagged)
chunked.draw()
except Exception as e:
print(str(e))
process_content()
With this, you are given something like:
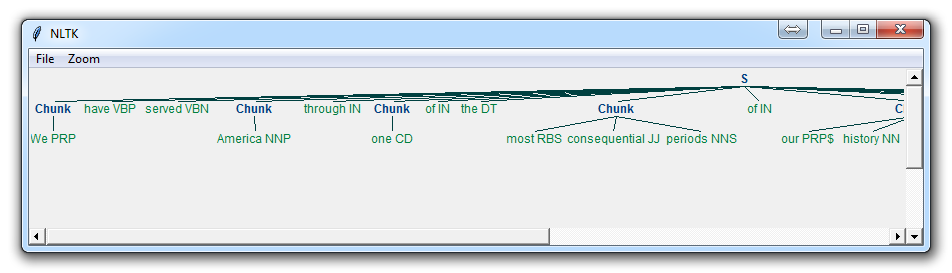
Now, the main difference here is:
}<VB.?|IN|DT|TO>+{
This means we're removing from the chink one or more verbs, prepositions, determiners, or the word 'to'.
Now that we've learned how to do some custom forms of chunking, and chinking, let's discuss a built-in form of chunking that comes with NLTK, and that is named entity recognition.
There exists 1 quiz/question(s) for this tutorial. for access to these, video downloads, and no ads.
-
Tokenizing Words and Sentences with NLTK
-
Stop words with NLTK
-
Stemming words with NLTK
-
Part of Speech Tagging with NLTK
-
Chunking with NLTK
-
Chinking with NLTK
-
Named Entity Recognition with NLTK
-
Lemmatizing with NLTK
-
The corpora with NLTK
-
Wordnet with NLTK
-
Text Classification with NLTK
-
Converting words to Features with NLTK
-
Naive Bayes Classifier with NLTK
-
Saving Classifiers with NLTK
-
Scikit-Learn Sklearn with NLTK
-
Combining Algorithms with NLTK
-
Investigating bias with NLTK
-
Improving Training Data for sentiment analysis with NLTK
-
Creating a module for Sentiment Analysis with NLTK
-
Twitter Sentiment Analysis with NLTK
-
Graphing Live Twitter Sentiment Analysis with NLTK with NLTK
-
Named Entity Recognition with Stanford NER Tagger
-
Testing NLTK and Stanford NER Taggers for Accuracy
-
Testing NLTK and Stanford NER Taggers for Speed
-
Using BIO Tags to Create Readable Named Entity Lists
