Q-Learning In Our Own Custom Environment - Reinforcement Learning w/ Python Tutorial p.4
Welcome to part 4 of the Reinforcement Learning series as well our our Q-learning part of it. In this part, we're going to wrap up this basic Q-Learning by making our own environment to learn in. I hadn't initially intended to do this as a tutorial, it was just something I personally wanted to do, but, after many requests, it only makes sense to do it as a tutorial!
If you've followed my tutorials much over the years, you know I like blobs. I like the player blobs, food, and bad enemy blobs! It's kind of a staple in my examples. It's only fitting that blobs show up here.
The plan is to have a player blob (blue), which aims to navigate its way as quickly as possible to the food blob (green), while avoiding the enemy blob (red).
Now, we could make this super smooth with high definition, but we already know we're going to be breaking it down into observation spaces. Instead, let's just start in a discrete space. Something between a 10x10 and 20x20 should suffice. Do note, the larger you go, the larger your Q-Table will be in terms of space it takes up in memory as well as time it takes for the model to actually learn.
So, our environment will be a 20 x 20 grid, where we have 1 player, 1 enemy, and 1 food. For now, we'll just have the player able to move, in attempt to reach the food, which will yield a reward.
Let's begin with the imports we're going to be using:
import numpy as np # for array stuff and random
from PIL import Image # for creating visual of our env
import cv2 # for showing our visual live
import matplotlib.pyplot as plt # for graphing our mean rewards over time
import pickle # to save/load Q-Tables
from matplotlib import style # to make pretty charts because it matters.
import time # using this to keep track of our saved Q-Tables.
style.use("ggplot") # setting our style!
Next, we need to decide on an environment size. We're making a square grid here. As noted before, size will make a massive impact on our learning time.
A 10x10 Q-Table for example, in this case, is ~15MB. A 20x20 is ~195MB
To begin, let's go with a size of 10, just so we can learn this decade.
SIZE = 10
Great, now for a bunch of other constants and a few vars:
HM_EPISODES = 25000
MOVE_PENALTY = 1 # feel free to tinker with these!
ENEMY_PENALTY = 300 # feel free to tinker with these!
FOOD_REWARD = 25 # feel free to tinker with these!
epsilon = 0.5 # randomness
EPS_DECAY = 0.9999 # Every episode will be epsilon*EPS_DECAY
SHOW_EVERY = 1000 # how often to play through env visually.
start_q_table = None # if we have a pickled Q table, we'll put the filename of it here.
LEARNING_RATE = 0.1
DISCOUNT = 0.95
PLAYER_N = 1 # player key in dict
FOOD_N = 2 # food key in dict
ENEMY_N = 3 # enemy key in dict
# the dict! Using just for colors
d = {1: (255, 175, 0), # blueish color
2: (0, 255, 0), # green
3: (0, 0, 255)} # red
These should all be self-explanatory, otherwise the comments should cover it. If you don't know what something like LEARNING_RATE or DISCOUNT means, then you should start back at the beginning of this series.
Next this environment consists of blobs. These "blobs" are really just going to be squares, but, I am calling them blobs, alright?
class Blob:
def __init__(self):
self.x = np.random.randint(0, SIZE)
self.y = np.random.randint(0, SIZE)
So, we'll begin by initializing the blobs randomly. We could have the unfortunate environment where the enemy and our blob, or the enemy and the food, are on the same "tile" so to speak. Tough luck. For debugging purposes, I wanted a string method:
def __str__(self):
return f"{self.x}, {self.y}"
Next, we're going to do some operator overloading to help us with our observations.
We need some sort of observation of our environment to use as our states. I propose we simply pass the x and y deltas for the food and enemy to our agent. To make this easy, I am going to override the - (subtraction) operator, so we can just subtract two blobs from each other. This method will look like:
def __sub__(self, other):
return (self.x-other.x, self.y-other.y)
The other there is any other blob type of object (or really anything with x and y attributes!
Next, I'm going to add an "action" method, which will move based on a "discrete" action being passed.
def action(self, choice):
'''
Gives us 4 total movement options. (0,1,2,3)
'''
if choice == 0:
self.move(x=1, y=1)
elif choice == 1:
self.move(x=-1, y=-1)
elif choice == 2:
self.move(x=-1, y=1)
elif choice == 3:
self.move(x=1, y=-1))
Now, we just need that move method:
def move(self, x=False, y=False):
# If no value for x, move randomly
if not x:
self.x += np.random.randint(-1, 2)
else:
self.x += x
# If no value for y, move randomly
if not y:
self.y += np.random.randint(-1, 2)
else:
self.y += y
# If we are out of bounds, fix!
if self.x < 0:
self.x = 0
elif self.x > SIZE-1:
self.x = SIZE-1
if self.y < 0:
self.y = 0
elif self.y > SIZE-1:
self.y = SIZE-1
The comments and code there should be pretty easy to follow. We're just moving randomly if we don't get any values for x/y, otherwise we move based on the requested moves. Then, we finally control for attempts for the blob to go out of bounds.
Now, we could test what we've got so far. For example:
player = Blob() food = Blob() enemy = Blob() print(player) print(food) print(player-food) player.move() print(player-food) player.action(2) print(player-food)
7, 5 8, 1 (-1, 4) (-2, 5) (-3, 6) >>>
Looks like things are working so far! Let's make the q_table now:
if start_q_table is None:
# initialize the q-table#
q_table = {}
for i in range(-SIZE+1, SIZE):
for ii in range(-SIZE+1, SIZE):
for iii in range(-SIZE+1, SIZE):
for iiii in range(-SIZE+1, SIZE):
q_table[((i, ii), (iii, iiii))] = [np.random.uniform(-5, 0) for i in range(4)]
This isn't the most efficient code ever, but it should cover all of our basis. Despite the table being pretty large for Q-Learning, Python should still be able to make quick work of generating a table of this size. Takes about 2 seconds for me, and is an operation that needs to just run once, so that's fine with me. Feel free to improve it!
Once we have started training, however, we may actually have a Q-Table saved already, so we'll handle for if we've set a filename for that Q-table:
else:
with open(start_q_table, "rb") as f:
q_table = pickle.load(f)
For note, to look up on your Q-table, you would do something like:
print(q_table[((-9, -2), (3, 9))])
Okay, we're ready to start iterating over episodes!
episode_rewards = []
for episode in range(HM_EPISODES):
player = Blob()
food = Blob()
enemy = Blob()
We will start tracking the episode rewards and their improvements over time with episode_rewards. For each new episode, we re-initialize the player, food, and enemy objects. Next, let's handle the logic to visualize or not:
if episode % SHOW_EVERY == 0:
print(f"on #{episode}, epsilon is {epsilon}")
print(f"{SHOW_EVERY} ep mean: {np.mean(episode_rewards[-SHOW_EVERY:])}")
show = True
else:
show = False
Now we start the actual frames/steps of the episode:
episode_reward = 0
for i in range(200):
obs = (player-food, player-enemy)
#print(obs)
if np.random.random() > epsilon:
# GET THE ACTION
action = np.argmax(q_table[obs])
else:
action = np.random.randint(0, 4)
# Take the action!
player.action(action)
I will also point out, here is where we might opt to move the other objects:
#### MAYBE ###
#enemy.move()
#food.move()
##############
It is my suspicion though that moving these will harm training initially, and my expectation is that we would maybe move them after already having trained quite a bit, or maybe just moving after training entirely. The same algorithm trained with movement off for food/enemy should be able to work with those things moving. I just think those things moving will confuse the algorithm's learning.
Now we'll handle for the rewarding:
if player.x == enemy.x and player.y == enemy.y:
reward = -ENEMY_PENALTY
elif player.x == food.x and player.y == food.y:
reward = FOOD_REWARD
else:
reward = -MOVE_PENALTY
Once we have the reward info, we can work up our Q-table and Q-value information:
new_obs = (player-food, player-enemy) # new observation
max_future_q = np.max(q_table[new_obs]) # max Q value for this new obs
current_q = q_table[obs][action] # current Q for our chosen action
With these values, we can do our calculations:
if reward == FOOD_REWARD:
new_q = FOOD_REWARD
else:
new_q = (1 - LEARNING_RATE) * current_q + LEARNING_RATE * (reward + DISCOUNT * max_future_q)
While we don't actually have to visualize this environment, it would help us to make sure we aren't making some mistake.
Who am I kidding, we just want to see our awesome creation!!
...but we don't want to see it for every episode, since we'll have many of those.
if show:
env = np.zeros((SIZE, SIZE, 3), dtype=np.uint8) # starts an rbg of our size
env[food.x][food.y] = d[FOOD_N] # sets the food location tile to green color
env[player.x][player.y] = d[PLAYER_N] # sets the player tile to blue
env[enemy.x][enemy.y] = d[ENEMY_N] # sets the enemy location to red
img = Image.fromarray(env, 'RGB') # reading to rgb. Apparently. Even tho color definitions are bgr. ???
img = img.resize((300, 300)) # resizing so we can see our agent in all its glory.
cv2.imshow("image", np.array(img)) # show it!
if reward == FOOD_REWARD or reward == -ENEMY_PENALTY: # crummy code to hang at the end if we reach abrupt end for good reasons or not.
if cv2.waitKey(500) & 0xFF == ord('q'):
break
else:
if cv2.waitKey(1) & 0xFF == ord('q'):
break
Comments should explain the above code. Next, we want to handle for our rewards:
episode_reward += reward
Then break if we either reached objective or hit our enemy!
if reward == FOOD_REWARD or reward == -ENEMY_PENALTY:
break
After all of this, we tab back one, and finish out our per-episode loop:
episode_rewards.append(episode_reward)
epsilon *= EPS_DECAY
The entire episodes loop looks like:
episode_rewards = []
for episode in range(HM_EPISODES):
player = Blob()
food = Blob()
enemy = Blob()
if episode % SHOW_EVERY == 0:
print(f"on #{episode}, epsilon is {epsilon}")
print(f"{SHOW_EVERY} ep mean: {np.mean(episode_rewards[-SHOW_EVERY:])}")
show = True
else:
show = False
episode_reward = 0
for i in range(200):
obs = (player-food, player-enemy)
#print(obs)
if np.random.random() > epsilon:
# GET THE ACTION
action = np.argmax(q_table[obs])
else:
action = np.random.randint(0, 4)
# Take the action!
player.action(action)
#### MAYBE ###
#enemy.move()
#food.move()
##############
if player.x == enemy.x and player.y == enemy.y:
reward = -ENEMY_PENALTY
elif player.x == food.x and player.y == food.y:
reward = FOOD_REWARD
else:
reward = -MOVE_PENALTY
## NOW WE KNOW THE REWARD, LET'S CALC YO
# first we need to obs immediately after the move.
new_obs = (player-food, player-enemy)
max_future_q = np.max(q_table[new_obs])
current_q = q_table[obs][action]
if reward == FOOD_REWARD:
new_q = FOOD_REWARD
else:
new_q = (1 - LEARNING_RATE) * current_q + LEARNING_RATE * (reward + DISCOUNT * max_future_q)
q_table[obs][action] = new_q
if show:
env = np.zeros((SIZE, SIZE, 3), dtype=np.uint8) # starts an rbg of our size
env[food.x][food.y] = d[FOOD_N] # sets the food location tile to green color
env[player.x][player.y] = d[PLAYER_N] # sets the player tile to blue
env[enemy.x][enemy.y] = d[ENEMY_N] # sets the enemy location to red
img = Image.fromarray(env, 'RGB') # reading to rgb. Apparently. Even tho color definitions are bgr. ???
img = img.resize((300, 300)) # resizing so we can see our agent in all its glory.
cv2.imshow("image", np.array(img)) # show it!
if reward == FOOD_REWARD or reward == -ENEMY_PENALTY: # crummy code to hang at the end if we reach abrupt end for good reasons or not.
if cv2.waitKey(500) & 0xFF == ord('q'):
break
else:
if cv2.waitKey(1) & 0xFF == ord('q'):
break
episode_reward += reward
if reward == FOOD_REWARD or reward == -ENEMY_PENALTY:
break
#print(episode_reward)
episode_rewards.append(episode_reward)
epsilon *= EPS_DECAY
Now we can finally just graph and save things:
moving_avg = np.convolve(episode_rewards, np.ones((SHOW_EVERY,))/SHOW_EVERY, mode='valid')
plt.plot([i for i in range(len(moving_avg))], moving_avg)
plt.ylabel(f"Reward {SHOW_EVERY}ma")
plt.xlabel("episode #")
plt.show()
with open(f"qtable-{int(time.time())}.pickle", "wb") as f:
pickle.dump(q_table, f)
Full code is now:
import numpy as np
from PIL import Image
import cv2
import matplotlib.pyplot as plt
import pickle
from matplotlib import style
import time
style.use("ggplot")
SIZE = 10
HM_EPISODES = 25000
MOVE_PENALTY = 1
ENEMY_PENALTY = 300
FOOD_REWARD = 25
epsilon = 0.9
EPS_DECAY = 0.9998 # Every episode will be epsilon*EPS_DECAY
SHOW_EVERY = 3000 # how often to play through env visually.
start_q_table = None # None or Filename
LEARNING_RATE = 0.1
DISCOUNT = 0.95
PLAYER_N = 1 # player key in dict
FOOD_N = 2 # food key in dict
ENEMY_N = 3 # enemy key in dict
# the dict!
d = {1: (255, 175, 0),
2: (0, 255, 0),
3: (0, 0, 255)}
class Blob:
def __init__(self):
self.x = np.random.randint(0, SIZE)
self.y = np.random.randint(0, SIZE)
def __str__(self):
return f"{self.x}, {self.y}"
def __sub__(self, other):
return (self.x-other.x, self.y-other.y)
def action(self, choice):
'''
Gives us 4 total movement options. (0,1,2,3)
'''
if choice == 0:
self.move(x=1, y=1)
elif choice == 1:
self.move(x=-1, y=-1)
elif choice == 2:
self.move(x=-1, y=1)
elif choice == 3:
self.move(x=1, y=-1)
def move(self, x=False, y=False):
# If no value for x, move randomly
if not x:
self.x += np.random.randint(-1, 2)
else:
self.x += x
# If no value for y, move randomly
if not y:
self.y += np.random.randint(-1, 2)
else:
self.y += y
# If we are out of bounds, fix!
if self.x < 0:
self.x = 0
elif self.x > SIZE-1:
self.x = SIZE-1
if self.y < 0:
self.y = 0
elif self.y > SIZE-1:
self.y = SIZE-1
if start_q_table is None:
# initialize the q-table#
q_table = {}
for i in range(-SIZE+1, SIZE):
for ii in range(-SIZE+1, SIZE):
for iii in range(-SIZE+1, SIZE):
for iiii in range(-SIZE+1, SIZE):
q_table[((i, ii), (iii, iiii))] = [np.random.uniform(-5, 0) for i in range(4)]
else:
with open(start_q_table, "rb") as f:
q_table = pickle.load(f)
# can look up from Q-table with: print(q_table[((-9, -2), (3, 9))]) for example
episode_rewards = []
for episode in range(HM_EPISODES):
player = Blob()
food = Blob()
enemy = Blob()
if episode % SHOW_EVERY == 0:
print(f"on #{episode}, epsilon is {epsilon}")
print(f"{SHOW_EVERY} ep mean: {np.mean(episode_rewards[-SHOW_EVERY:])}")
show = True
else:
show = False
episode_reward = 0
for i in range(200):
obs = (player-food, player-enemy)
#print(obs)
if np.random.random() > epsilon:
# GET THE ACTION
action = np.argmax(q_table[obs])
else:
action = np.random.randint(0, 4)
# Take the action!
player.action(action)
#### MAYBE ###
#enemy.move()
#food.move()
##############
if player.x == enemy.x and player.y == enemy.y:
reward = -ENEMY_PENALTY
elif player.x == food.x and player.y == food.y:
reward = FOOD_REWARD
else:
reward = -MOVE_PENALTY
## NOW WE KNOW THE REWARD, LET'S CALC YO
# first we need to obs immediately after the move.
new_obs = (player-food, player-enemy)
max_future_q = np.max(q_table[new_obs])
current_q = q_table[obs][action]
if reward == FOOD_REWARD:
new_q = FOOD_REWARD
else:
new_q = (1 - LEARNING_RATE) * current_q + LEARNING_RATE * (reward + DISCOUNT * max_future_q)
q_table[obs][action] = new_q
if show:
env = np.zeros((SIZE, SIZE, 3), dtype=np.uint8) # starts an rbg of our size
env[food.x][food.y] = d[FOOD_N] # sets the food location tile to green color
env[player.x][player.y] = d[PLAYER_N] # sets the player tile to blue
env[enemy.x][enemy.y] = d[ENEMY_N] # sets the enemy location to red
img = Image.fromarray(env, 'RGB') # reading to rgb. Apparently. Even tho color definitions are bgr. ???
img = img.resize((300, 300)) # resizing so we can see our agent in all its glory.
cv2.imshow("image", np.array(img)) # show it!
if reward == FOOD_REWARD or reward == -ENEMY_PENALTY: # crummy code to hang at the end if we reach abrupt end for good reasons or not.
if cv2.waitKey(500) & 0xFF == ord('q'):
break
else:
if cv2.waitKey(1) & 0xFF == ord('q'):
break
episode_reward += reward
if reward == FOOD_REWARD or reward == -ENEMY_PENALTY:
break
#print(episode_reward)
episode_rewards.append(episode_reward)
epsilon *= EPS_DECAY
moving_avg = np.convolve(episode_rewards, np.ones((SHOW_EVERY,))/SHOW_EVERY, mode='valid')
plt.plot([i for i in range(len(moving_avg))], moving_avg)
plt.ylabel(f"Reward {SHOW_EVERY}ma")
plt.xlabel("episode #")
plt.show()
with open(f"qtable-{int(time.time())}.pickle", "wb") as f:
pickle.dump(q_table, f)
You should see some examples playing, then get a graph at the end, like:
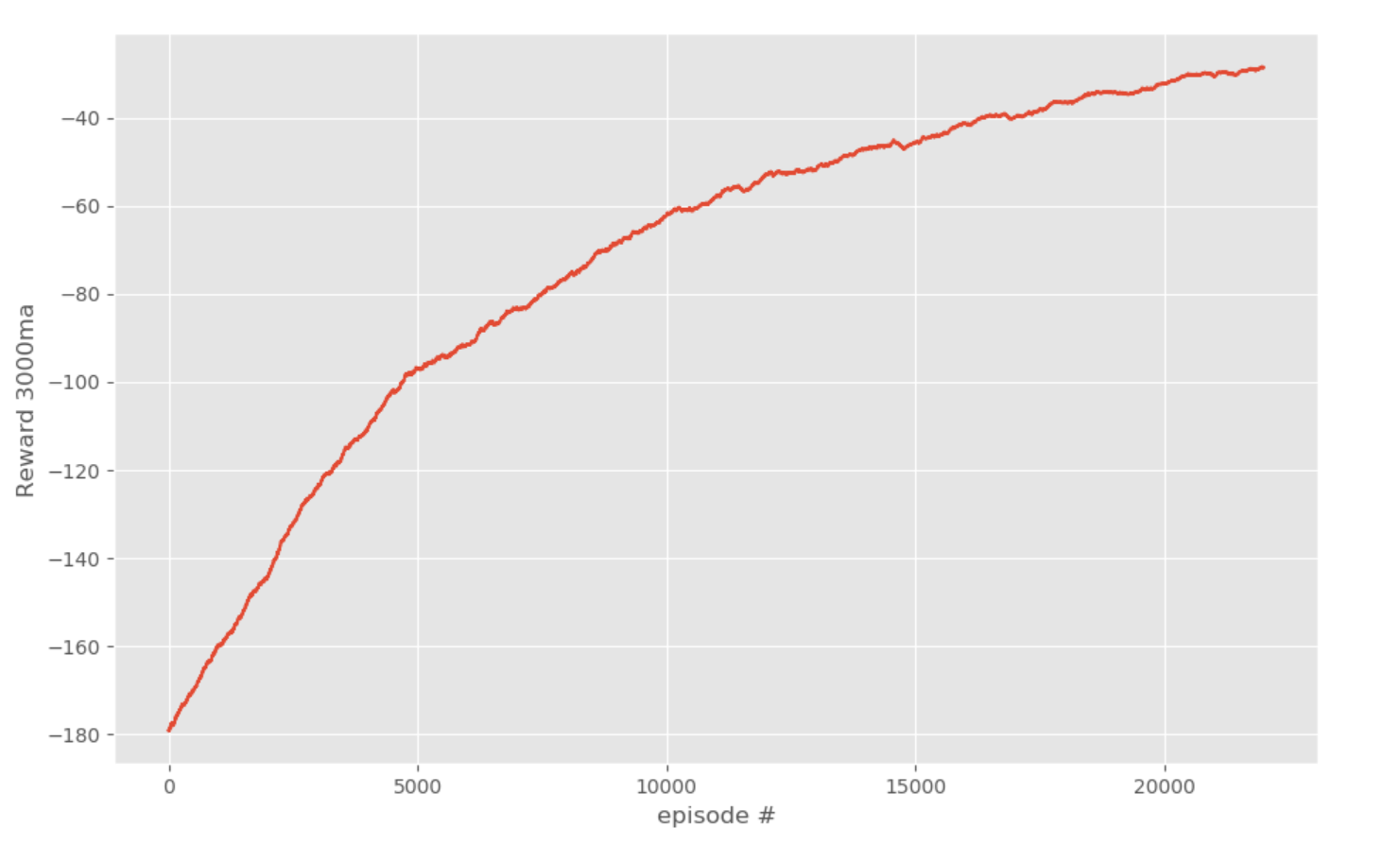
After closing that graph, the q-table will save, along with the timestamp of that Q-Table. Now, we can load in this table, and either play, learn, or both. For example, we can just change SHOW_EVERY to 1:
SHOW_EVERY = 1
Then epsilon to 0:
epsilon = 0.0
Then, we can see a result like:
Not quite the smartest thing I've ever seen. Let's keep training. First, we update:
start_q_table = "qtable-1559485134.pickle" # None or Filename
Make sure your timestamp is correct, don't just copy mine. I am going to set:
HM_EPISODES = 50000
Then start epsilon back to 1.
epsilon = 1.0
Then SHOW_EVERY back to:
SHOW_EVERY = 5000 # how often to play through env visually.
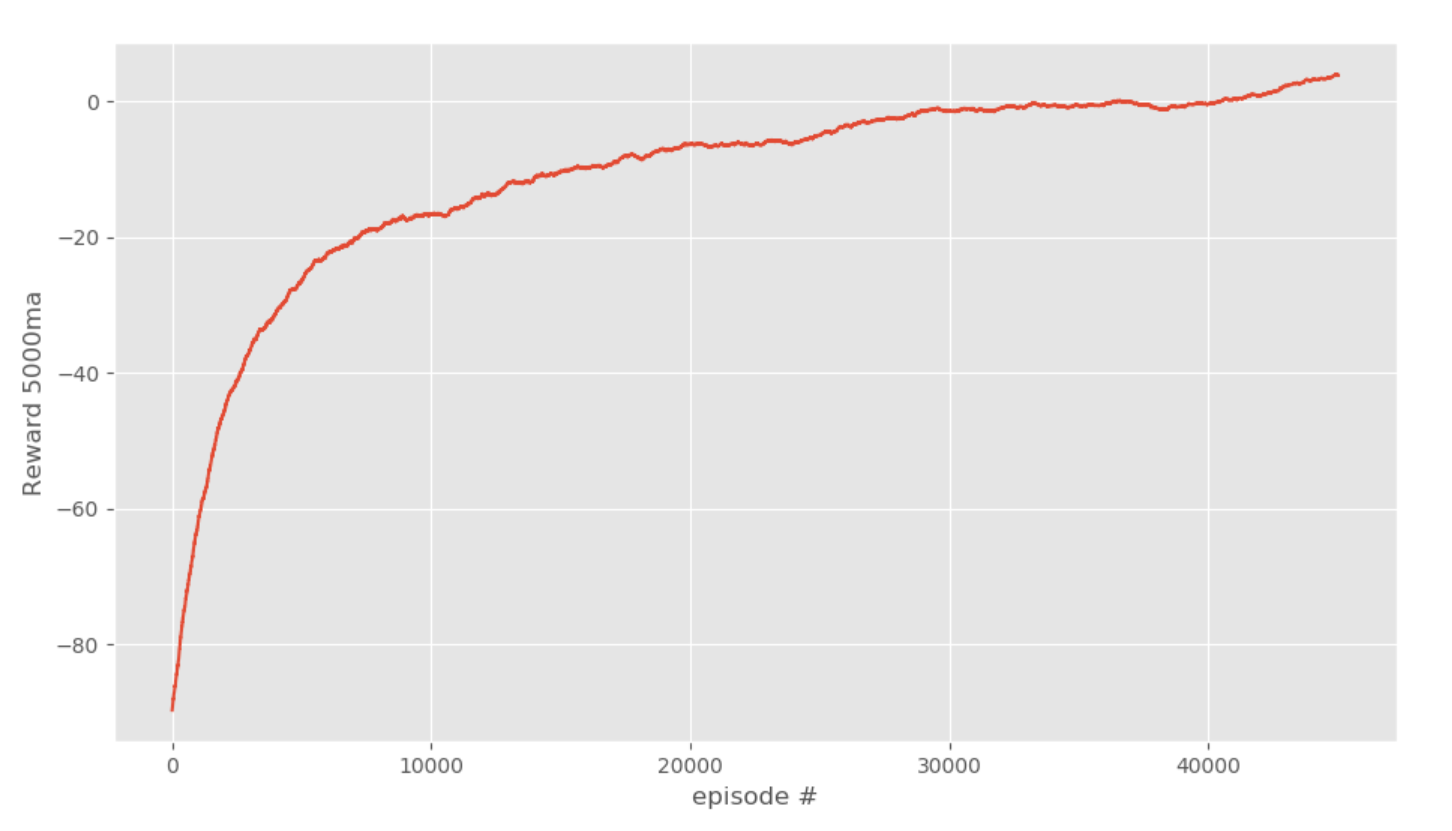
Okay, load in the new Q-table, set epsilon to 0, show every to 1, and let's see how we're doing.
Alright! I'd say we've solved it. Looks awesome!
...but what about movement? Let's try to just turn that on.
#### Movement for food and enemy ###
enemy.move()
food.move()
##############
Inside the step loop (for i in range(200)).
So you can see here it actually works with movement on right out of the box, since the model really is just trained to move based on relative position deltas. One thing this model isn't prepared for, however, is if the enemy is close, that in theory, the enemy and player could move on to the same tile. In all of training, the player could move all around the enemy safely. With movement on, this is not the case, so you'd still likely want to train with movement on from here, and maybe you'd see some new capabilities of the player emerge.
I wanted to see how much of a difference going from 10x10 to a 20x20 would make. As we saw, somewhere between 25k and 75K training episodes were required for the 10x10 to learn. I found it took more like 2.5 million episodes for a 20x20 model to learn.
Luckily, episodes don't take very long to train, so this still isn't a big deal. If you're curious, here are the results:
No movement for enemy/food:
Movement on for enemy and food:
It was after I shared this code with Daniel that he suggested the blob should only be able to reach food ~half the time, since movements could only be diagonal. This is actually... a good point. I had not considered this when I was coding it, I just wanted to keep the action space smaller.
If the food's x is even and the player's x is odd...or same for y, then it would be impossible to move directly to the food.
...unless we use the wall. The problem is the player doesn't actually know about a wall, or even their location in the environment. The only thing the player knows is the relative position to the food and enemy. So, even a subtle property like needing to use the wall would require the agent to move all the way up/down/left/right to compensate for a difference in x or y even/odd issues. I'm actually quite shocked that the agent could learn this. The success rate is nearly perfect with both movement on and not, depsite this fundamental issue that I would not have expected Q-Learning to be able to handle for so easily.
I encourage you to tinker more with this environment. We have lots of things like the size, rewards, punishments, possible actions, and even observations that could be tweaked.
-
Q-Learning introduction and Q Table - Reinforcement Learning w/ Python Tutorial p.1
-
Q Algorithm and Agent (Q-Learning) - Reinforcement Learning w/ Python Tutorial p.2
-
Q-Learning Analysis - Reinforcement Learning w/ Python Tutorial p.3
-
Q-Learning In Our Own Custom Environment - Reinforcement Learning w/ Python Tutorial p.4
-
Deep Q Learning and Deep Q Networks (DQN) Intro and Agent - Reinforcement Learning w/ Python Tutorial p.5
-
Training Deep Q Learning and Deep Q Networks (DQN) Intro and Agent - Reinforcement Learning w/ Python Tutorial p.6
