Longer-term model results - Self-driving cars with Carla and Python
Welcome to part 6 of the self-driving cars/autonomous cars and reinforcement learning with Carla, Python, and TensorFlow. In this part, we'll talk about some of the preliminary findings of our work. I will use the phrase "we" since this a join effort between me and Daniel Kukiela.
To begin, the problem was purposefully kept very simple. The agent could take one of three total actions: Turn Left, Turn Right, Go straight.
I went with the Xception model, since I found success with that model and doing self-driving cars in GTA.
For rewards, we setup the following:
- +1 for each frame driving > 50KMH
- -1 for each frame driving < 50KMH
- -200 for a collision and episode is over
The first thing we discovered was that both loss and q values were basically exploding:
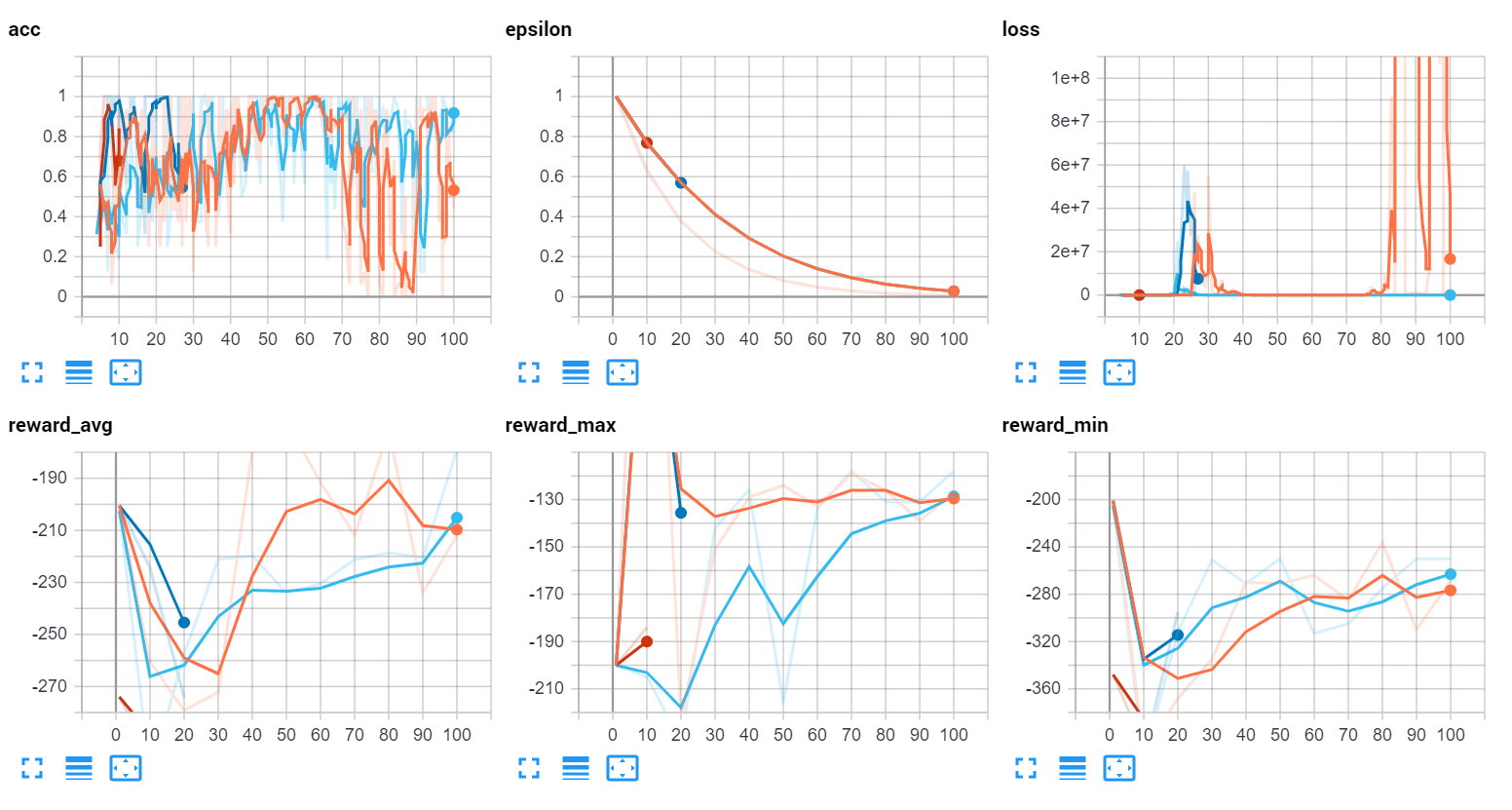
This was seemingly, and now obviously, due to the monumental size of the crash penalty in comparison to all else. Also possibly the bounds being out of range. For example, we might have had more success by doing something more like:
- +0.005 (1/200) for each frame driving > 50KMH
- -0.005 (-1/200) for each frame driving < 50KMH
- -1 (-200/200) for a collision and episode is over
But instead we just went with:
- +1 for each frame driving > 50KMH
- -1 for each frame driving < 50KMH
- -1 for a collision and episode is over
This seemed to curtail the explosiveness of Q values and loss, but we still found agents would undoubtedly go with only 1 action constantly when given 0 epsilon.
We then attempted to feed in speed to the neural network as well. This seemed to help a bit, but still wasn't the main problem.
So then we considered the model. Probably should have considered this earlier. Reinforcement learning is quite a bit different from supervised learning, mainly in the fact that supervised learning is pure ground-truth (or at least that's the expectation). All imagery you feed it, and the labels, are meant to be 100% accurate. With reinforcement learning, this isn't really the case. We're fitting a model, yes, but we're also fitting for these Q values. It's far more complex operation going on, and things are going to be a bit more "fuzzy" to the model. No reason to also have a highly complex neural network. When we examine the Xception model (with our speed layer), it has basically 23 million trainable parameters:
Total params: 22,962,155 Trainable params: 22,907,627 Non-trainable params: 54,528
That's a lot!
And we were finding that our accuracy for the model was quite high (like 80-95%), so this tells me that we were almost certainly just overfitting every time.
Okay, so what do we do then? We'll, historically given evolutionary type models that I've used with success have been 64x3 convnets. So why not do that again. So a 64x3 convolutional neural network is more like 3 million trainable parameters in this case (including speed layer and such):
Total params: 3,024,643 Trainable params: 3,024,643 Non-trainable params: 0
def model_base_64x3_CNN(input_shape):
model = Sequential()
model.add(Conv2D(64, (3, 3), input_shape=input_shape, padding='same'))
model.add(Activation('relu'))
model.add(AveragePooling2D(pool_size=(5, 5), strides=(3, 3), padding='same'))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(AveragePooling2D(pool_size=(5, 5), strides=(3, 3), padding='same'))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(AveragePooling2D(pool_size=(5, 5), strides=(3, 3), padding='same'))
model.add(Flatten())
return model.input, model.output
A much simpler model.
This model was trained like this for a few days, yielding:

I will show the stats a bit at a time, since we were tracking a lot of stats. So first off we have accuracy. With a DQN, you're not as obsessed with accuracy being good as you might otherwise be with something like supervised learning. It's important, but really you just want something decent. If your model is something like 90% accurate, this would really be something to be highly suspicious about, rather than happy. Remember, your agent is taking a large # of just plain random actions, and is slowly *learning* the Q values. The neural network is part of the operation, but a highly accurate neural network, especially in the beginning would be a red flag.
FPS is important. When it comes to something like driving a car, the higher the FPS the better. We aimed to average around 15FPS, controlling it by how many agents we decided to spawn. If you can barely run even just 1 agent, then you don't have much ability to tinker here.
Next, I show epsilon merely to show my attempts to explore some more. Sometimes it looked like it helped, other times not really.
Then finally the loss rate. Mostly just to show there were no explosions.
Then we can check out various stats about our rewards:
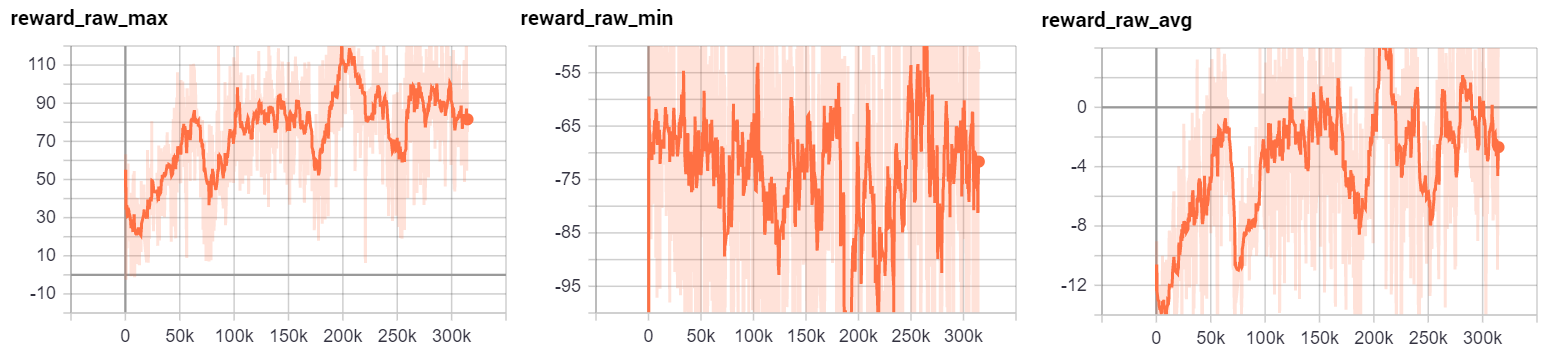
We can see that the max reward over time does trend up until 200,000 episodes, and may have continued back up given more time. The minimum reward (ie: the worst an agent did), didn't seem to change trend-wise, which isn't too shocking. Sometimes the car is just dropped into an unfortunate setting. Finally, we can see that the reward average improved pretty consistently. At the moment, it has slipped, but not for necessarily longer than it historically did a few times.
Overall, the model did improve, and this 64x3 CNN turned out to be our best performing model, but we did try quite a few other things:
More cities. There are 7 total cities to choose from, so we cycled the city to a random city every 10 episodes. My wonder here was if this would help with more generalization than to be just in one city. It didn't seem to help.
Allow more actions. So the agent originally was always full throttle and could only go left, right, or straight. We then gave it the option for braking and such, to see if this might help. It did not.
We tinkered with the reward function, adding in different elements of time and speed, making far more complex ones than simply a threshold of speed required for a reward. We found the best agent to have a time-weighted reward function, with the 50KMH threshold.
In the end, it really may just be the case that more time is required. A DQN can be extremely good at learning things.... just not quickly. I'd like to keep training the agent for a while to see if it continues to improve or not, but I had to eventually release this update, and it wasn't just this agent that we spent time training. If you've tinkered at all with Carla and using a DQN on really any complicated env, then you understand how long it takes to train just one model, much less trying to train many different models with different parameters! This model alone took 125 hours, or over 5 days to train.
If you want to play with things to see if you can do it better, check out: Carla-RL github
-
Introduction - Self-driving cars with Carla and Python part 1
-
Controlling the Car and getting sensor data - Self-driving cars with Carla and Python part 2
-
Reinforcement Learning Environment - Self-driving cars with Carla and Python part 3
-
Reinforcement Learning Agent - Self-driving cars with Carla and Python part 4
-
Reinforcement Learning in Action - Self-driving cars with Carla and Python part 5
-
Longer-term model results - Self-driving cars with Carla and Python
