Introduction to Deep Learning - Deep Learning basics with Python, TensorFlow and Keras p.1
Welcome everyone to an updated deep learning with Python and Tensorflow tutorial mini-series.
Since doing the first deep learning with TensorFlow course a little over 2 years ago, much has changed. It's nowhere near as complicated to get started, nor do you need to know as much to be successful with deep learning.
If you're interested in more of the details with how TensorFlow works, you can still check out the previous tutorials, as they go over the more raw TensorFlow. This is more of a deep learning quick start!
To begin, we need to find some balance between treating neural networks like a total black box, and understanding every single detail with them.
Let's show a typical model:
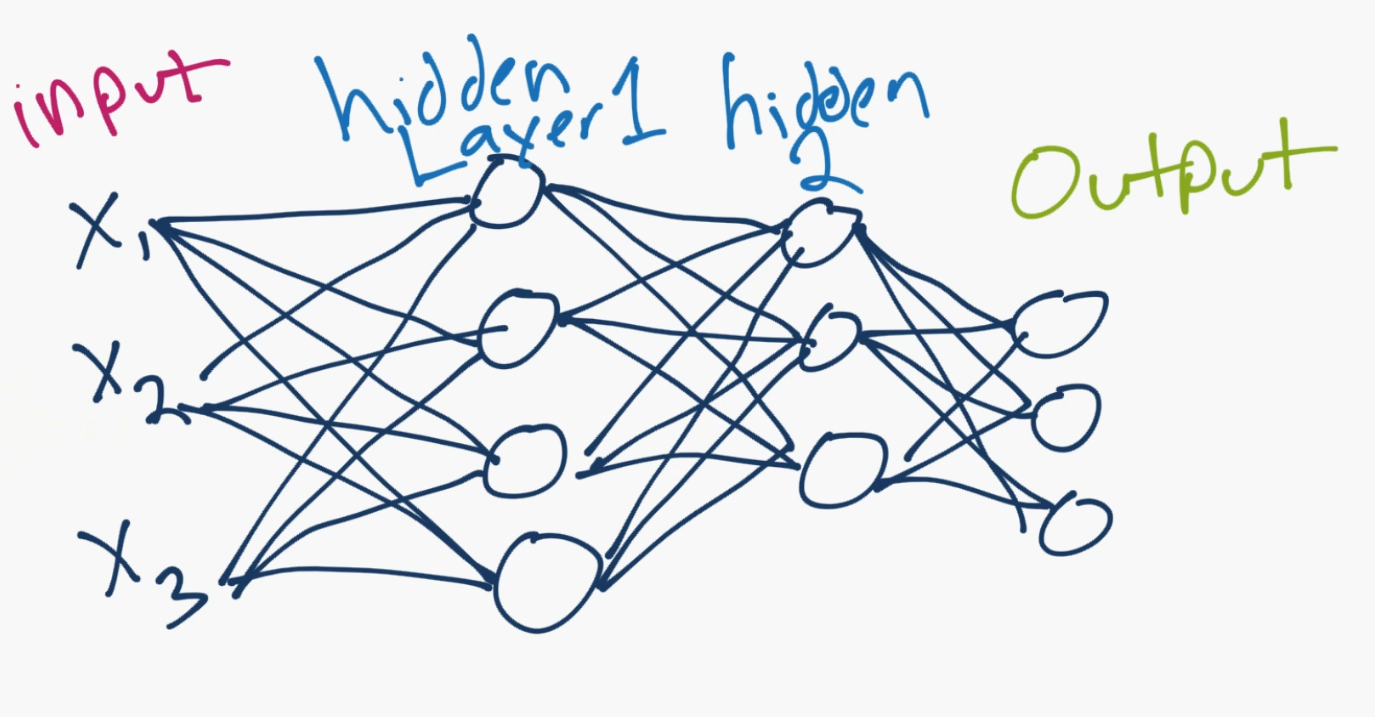
A basic neural network consists of an input layer, which is just your data, in numerical form. After your input layer, you will have some number of what are called "hidden" layers. A hidden layer is just in between your input and output layers. One hidden layer means you just have a neural network. Two or more hidden layers? Boom, you've got a deep neural network!
Why is this? Well, if you just have a single hidden layer, the model is going to only learn linear relationships.
If you have many hidden layers, you can begin to learn non-linear relationships between your input and output layers.
A single neuron might look as follows:
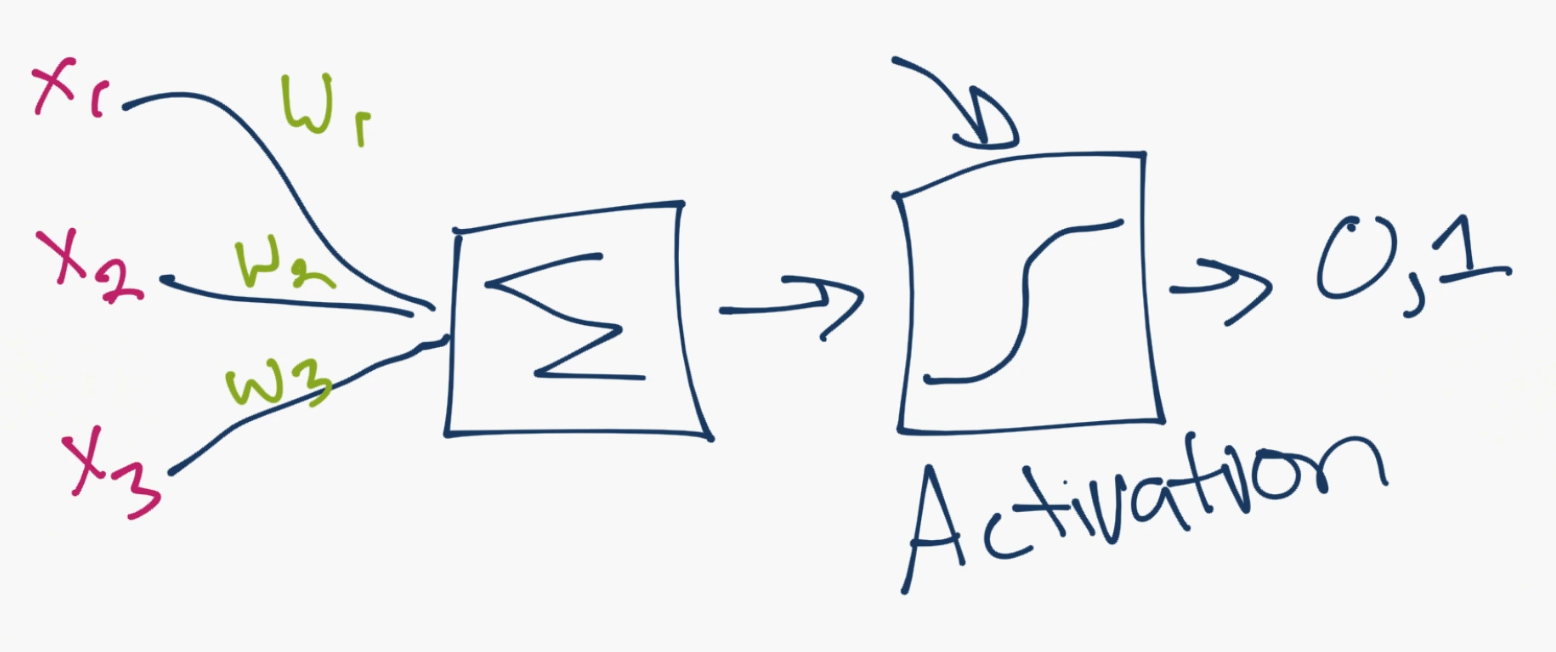
So this is really where the magic happens. The idea is a single neuron is just sum of all of the inputs x weights, fed through some sort of activation function. The activation function is meant to simulate a neuron firing or not. A simple example would be a stepper function, where, at some point, the threshold is crossed, and the neuron fires a 1, else a 0. Let's say that neuron is in the first hidden layer, and it's going to communicate with the next hidden layer. So it's going to send it's 0 or a 1 signal, multiplied by the weights, to the next neuron, and this is the process for all neurons and all layers.
The mathematical challenge for the artificial neural network is to best optimize thousands or millions or whatever number of weights you have, so that your output layer results in what you were hoping for. Solving for this problem, and building out the layers of our neural network model is exactly what TensorFlow is for. TensorFlow is used for all things "operations on tensors." A tensor in this case is nothing fancy. It's a multi-dimensional array.
To install TensorFlow, simply do a:
pip install --upgrade tensorflow
Following the release of deep learning libraries, higher-level API-like libraries came out, which sit on top of the deep learning libraries, like TensorFlow, which make building, testing, and tweaking models even more simple. One such library that has easily become the most popular is Keras.
Keras has become so popular, that it is now a superset, included with TensorFlow releases now! If you're familiar with Keras previously, you can still use it, but now you can use tensorflow.keras to call it. By that same token, if you find example code that uses Keras, you can use with the TensorFlow version of Keras too. In fact, you can just do something like:
import tensorflow.keras as keras
For this tutorial, I am going to be using TensorFlow version 1.10. You can figure out your version:
import tensorflow as tf
print(tf.__version__)
Once we've got tensorflow imported, we can then begin to prepare our data, model it, and then train it. For the sake of simplicity, we'll be using the most common "hello world" example for deep learning, which is the mnist dataset. It's a dataset of hand-written digits, 0 through 9. It's 28x28 images of these hand-written digits. We will show an example of using outside data as well, but, for now, let's load in this data:
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
When you're working with your own collected data, chances are, it wont be packaged up so nicely, and you'll spend a bit more time and effort on this step. But, for now, woo!
What exactly do we have here? Let's take a quick peak.
So the x_train data is the "features." In this case, the features are pixel values of the 28x28 images of these digits 0-9. The y_train is the label (is it a 0,1,2,3,4,5,6,7,8 or a 9?)
The testing variants of these variables is the "out of sample" examples that we will use. These are examples from our data that we're going to set aside, reserving them for testing the model.
Neural networks are exceptionally good at fitting to data, so much so that they will commonly over-fit the data. Our real hope is that the neural network doesn't just memorize our data and that it instead "generalizes" and learns the actual problem and patterns associated with it.
Let's look at this actual data:
print(x_train[0])
Alright, could we visualize this?
import matplotlib.pyplot as plt
plt.imshow(x_train[0],cmap=plt.cm.binary)
plt.show()
Okay, that makes sense. How about the value for y_train with the same index?
print(y_train[0])
It's generally a good idea to "normalize" your data. This typically involves scaling the data to be between 0 and 1, or maybe -1 and positive 1. In our case, each "pixel" is a feature, and each feature currently ranges from 0 to 255. Not quite 0 to 1. Let's change that with a handy utility function:
x_train = tf.keras.utils.normalize(x_train, axis=1)
x_test = tf.keras.utils.normalize(x_test, axis=1)
Let's peak one more time:
print(x_train[0])
plt.imshow(x_train[0],cmap=plt.cm.binary)
plt.show()

Alright, still a 5. Now let's build our model!
model = tf.keras.models.Sequential()
A sequential model is what you're going to use most of the time. It just means things are going to go in direct order. A feed forward model. No going backwards...for now.
Now, we'll pop in layers. Recall our neural network image? Was the input layer flat, or was it multi-dimensional? It was flat. So, we need to take this 28x28 image, and make it a flat 1x784. There are many ways for us to do this, but keras has a Flatten layer built just for us, so we'll use that.
model.add(tf.keras.layers.Flatten())
This will serve as our input layer. It's going to take the data we throw at it, and just flatten it for us. Next, we want our hidden layers. We're going to go with the simplest neural network layer, which is just a Dense layer. This refers to the fact that it's a densely-connected layer, meaning it's "fully connected," where each node connects to each prior and subsequent node. Just like our image.
model.add(tf.keras.layers.Dense(128, activation=tf.nn.relu))
This layer has 128 units. The activation function is relu, short for rectified linear. Currently, relu is the activation function you should just default to. There are many more to test for sure, but, if you don't know what to use, use relu to start.
Let's add another identical layer for good measure.
model.add(tf.keras.layers.Dense(128, activation=tf.nn.relu))
Now, we're ready for an output layer:
model.add(tf.keras.layers.Dense(10, activation=tf.nn.softmax))
This is our final layer. It has 10 nodes. 1 node per possible number prediction. In this case, our activation function is a softmax function, since we're really actually looking for something more like a probability distribution of which of the possible prediction options this thing we're passing features through of is. Great, our model is done.
Now we need to "compile" the model. This is where we pass the settings for actually optimizing/training the model we've defined.
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
Remember why we picked relu as an activation function? Same thing is true for the Adam optimizer. It's just a great default to start with.
Next, we have our loss metric. Loss is a calculation of error. A neural network doesn't actually attempt to maximize accuracy. It attempts to minimize loss. Again, there are many choices, but some form of categorical crossentropy is a good start for a classification task like this.
Now, we fit!
model.fit(x_train, y_train, epochs=3)
As we train, we can see loss goes down (yay), and accuracy improves quite quickly to 98-99% (double yay!)
Now that's loss and accuracy for in-sample data. Getting a high accuracy and low loss might mean your model learned how to classify digits in general (it generalized)...or it simply memorized every single example you showed it (it overfit). This is why we need to test on out-of-sample data (data we didn't use to train the model).
val_loss, val_acc = model.evaluate(x_test, y_test)
print(val_loss)
print(val_acc)
Full code up to this point, with some notes:
As of Dec 21st 2018, there's a known issue with the code. I am going to paste a snippet that you should use to replace the code with, should you be hitting an error:
(x_train, y_train), (x_test, y_test) = mnist.load_data() # 28x28 numbers of 0-9 x_train = tf.keras.utils.normalize(x_train, axis=1).reshape(x_train.shape[0], -1) x_test = tf.keras.utils.normalize(x_test, axis=1).reshape(x_test.shape[0], -1) model = tf.keras.models.Sequential() #model.add(tf.keras.layers.Flatten()) #Flatten the images! Could be done with numpy reshape model.add(tf.keras.layers.Dense(128, activation=tf.nn.relu, input_shape= x_train.shape[1:])) model.add(tf.keras.layers.Dense(128, activation=tf.nn.relu)) model.add(tf.keras.layers.Dense(10, activation=tf.nn.softmax)) #10 because dataset is numbers from 0 - 9
import tensorflow as tf # deep learning library. Tensors are just multi-dimensional arrays
mnist = tf.keras.datasets.mnist # mnist is a dataset of 28x28 images of handwritten digits and their labels
(x_train, y_train),(x_test, y_test) = mnist.load_data() # unpacks images to x_train/x_test and labels to y_train/y_test
x_train = tf.keras.utils.normalize(x_train, axis=1) # scales data between 0 and 1
x_test = tf.keras.utils.normalize(x_test, axis=1) # scales data between 0 and 1
model = tf.keras.models.Sequential() # a basic feed-forward model
model.add(tf.keras.layers.Flatten()) # takes our 28x28 and makes it 1x784
model.add(tf.keras.layers.Dense(128, activation=tf.nn.relu)) # a simple fully-connected layer, 128 units, relu activation
model.add(tf.keras.layers.Dense(128, activation=tf.nn.relu)) # a simple fully-connected layer, 128 units, relu activation
model.add(tf.keras.layers.Dense(10, activation=tf.nn.softmax)) # our output layer. 10 units for 10 classes. Softmax for probability distribution
model.compile(optimizer='adam', # Good default optimizer to start with
loss='sparse_categorical_crossentropy', # how will we calculate our "error." Neural network aims to minimize loss.
metrics=['accuracy']) # what to track
model.fit(x_train, y_train, epochs=3) # train the model
val_loss, val_acc = model.evaluate(x_test, y_test) # evaluate the out of sample data with model
print(val_loss) # model's loss (error)
print(val_acc) # model's accuracy
It's going to be very likely your accuracy out of sample is a bit worse, same with loss. In fact, it should be a red flag if it's identical, or better.
Finally, with your model, you can save it super easily:
model.save('epic_num_reader.model')
Load it back:
new_model = tf.keras.models.load_model('epic_num_reader.model')
finally, make predictions!
predictions = new_model.predict(x_test)
print(predictions)
Uwotm8?
That sure doesn't start off as helpful, but recall these are probability distributions. We can get the actual number pretty simply:
import numpy as np
print(np.argmax(predictions[0]))
There's your prediction, let's look at the input:
plt.imshow(x_test[0],cmap=plt.cm.binary)
plt.show()

Awesome! Okay, I think that covers all of the "quick start" types of things with Keras. This is just barely scratching the surface of what's available to you, so start poking around Tensorflow and Keras documentation.
Also check out the Machine Learning and Learn Machine Learning subreddits to stay up to date on news and information surrounding deep learning.
If you have further questions too, you can join our Python Discord. Til next time.
-
Introduction to Deep Learning - Deep Learning basics with Python, TensorFlow and Keras p.1
-
Loading in your own data - Deep Learning basics with Python, TensorFlow and Keras p.2
-
Convolutional Neural Networks - Deep Learning basics with Python, TensorFlow and Keras p.3
-
Analyzing Models with TensorBoard - Deep Learning basics with Python, TensorFlow and Keras p.4
-
Optimizing Models with TensorBoard - Deep Learning basics with Python, TensorFlow and Keras p.5
-
How to use your trained model - Deep Learning basics with Python, TensorFlow and Keras p.6
-
Recurrent Neural Networks - Deep Learning basics with Python, TensorFlow and Keras p.7
-
Creating a Cryptocurrency-predicting finance recurrent neural network - Deep Learning basics with Python, TensorFlow and Keras p.8
-
Normalizing and creating sequences for our cryptocurrency predicting RNN - Deep Learning basics with Python, TensorFlow and Keras p.9
-
Balancing Recurrent Neural Network sequence data for our crypto predicting RNN - Deep Learning basics with Python, TensorFlow and Keras p.10
-
Cryptocurrency-predicting RNN Model - Deep Learning basics with Python, TensorFlow and Keras p.11
