Interacting with our Chatbot - Creating a Chatbot with Deep Learning, Python, and TensorFlow Part 9
Welcome to part 9 chatbot with Tensorflow, Python, and deep learning tutorial series. In this tutorial, we're going to talk about how we can interact with our model, and possibly even push it into a production environment.
While your model trains, a checkpoint file is saved every 1,000 steps by default. Should you ever need or want to stop your training, you can safely do that and pick back up at the latest checkpoint. Data saved per checkpoint consists of various logging parameters, but also the full weights/biases...etc for your model. This means you can take these checkpoints/model files and use them to either continue training, or use them in production.
Checkpoints are saved by default in your model directory. You should see files called translate.ckpt-XXXXX, where the X's correspond to the step #. You should have a .data, .index, and a .meta file, along with a checkpoint file. If you open the checkpoint file, you'll see it looks like:
model_checkpoint_path: "/home/paperspace/Desktop/nmt-chatbot/model/translate.ckpt-225000" all_model_checkpoint_paths: "/home/paperspace/Desktop/nmt-chatbot/model/translate.ckpt-221000" all_model_checkpoint_paths: "/home/paperspace/Desktop/nmt-chatbot/model/translate.ckpt-222000" all_model_checkpoint_paths: "/home/paperspace/Desktop/nmt-chatbot/model/translate.ckpt-223000" all_model_checkpoint_paths: "/home/paperspace/Desktop/nmt-chatbot/model/translate.ckpt-224000" all_model_checkpoint_paths: "/home/paperspace/Desktop/nmt-chatbot/model/translate.ckpt-225000"
This just lets your model know which files to use. If you wanted to use a specific, older, model, you'd want to edit this.
So, to load in a model, we need 4 total files. Let's say our step is 225,000. This means we'd need the following to run our model, or load it to continue training:
checkpoint translate.ckpt-225000.meta translate.ckpt-225000.index translate.ckpt-225000.data-00000-of-00001
So if you move to a machine in the cloud, whether for training or for production, these are the files you'd need.
Along with saving checkpoints every 1,000 steps, we also do some more bulk examples (from our tst.to and tst.from files). These are output every few thousand steps, and come into the model directory as well as output_dev and output_test. You can use these files to see more than the single example that is done in console every 1,000 steps. These output files are purely the top output sentence result responses to your test files. Since you could have put any examples you wanted in your testing files, this is the very first way you'll likely interact with, or at least see interactions, with your chatbot to any significant degree. I wrote a simple pairing script to output the comment-response pairings of the testing files and output files.
For example, let's say you've got your tst2013.from file:
Aren ' t they streaming it for free online ... ? try to get loud please I ' m trying to eat a fajita here E It ' s been 3 innings and Spanton almost hit a dong . Looks - wise yes , play - wise no But we ' d both pay $ 9 . 9 9 to see that . newlinechar newlinechar Isn ' t he doing stuff for CZW ? Aren ' t they like extreme stuff , they should do a Punjabi Prison Match with CJ Parker . ' I simply feel as though the game is not for me . ' * Zaffre states , turning back to Ambrose , a frown on his face . * The fire escape is there . You hear wood splintering , and look to see that a raptor has managed to break a hole in the top of the door , just above the dresser . Its head pokes through , then disappears . There ' s another thud , and the dresser moves forward a few inches . [ ] ( / fritteehee ) I wonder how I ' ll make the eyes all red ... 3 6 0 , 6 7 8 I like the idea ... have an upvote ! who talks trash about Giannis ? C I ' m pretty sure that ' s the peace music . Did well on my quiz today , am now eating ice cream . Good day .
And then your output_dev file:
Yes they are . I don ' t think I ' ve ever heard of this . I ' ll have to check it out . <unk> R It ' s been a while since I ' ve seen it , but it ' s been a while since I ' ve seen it . I don ' t think I ' ve ever played - wise . I don ' t think he ' s doing anything for <unk> . I ' m sure he ' ll be fine . ' I don ' t feel as though the game is for me . ' That ' s what I was thinking as well . [ ] ( / <unk> ) I don ' t know . 3 6 0 , 6 7 9 Thank you ! I don ' t think that ' s what he ' s talking about . K You ' re right , it ' s the peace music . Good day .
We could manually go back and forth, but this can be quite tedious, so I have made a quick pairing script:
output_file_location = 'output_dev'
tst_file_location = 'tst2013.from'
if __name__ == '__main__':
with open(output_file_location,"r") as f:
content = f.read()
to_data = content.split('\n')
with open(tst_file_location,"r") as f:
content = f.read()
from_data = content.split('\n')
for n, _ in enumerate(to_data[:-1]):
print(30*'_')
print('>',from_data[n])
print()
print('Reply:',to_data[n])
Output should be something like:
______________________________ > Aren ' t they streaming it for free online ... ? Reply: Yes they are .
Next, you may want to actually communicate with your bot live, which is what the inference script is for.
If you run this, you can then interact with your bot, asking questions. At the time of my writing this, we're still tinkering with scoring outputs and tweaking things. You may be happy with the results here, or you might want to work on your own method for picking the "right" answer. For example, the chat bots that I've trained so far have had problems like just repeating the question, or sometimes not finishing a thought before the reply is done. Also, if the bot encounters a vocab term that isn't in their vocabulary, an UNK token will be produced, so we probably don't want those either.
If you want more than 10 plausible outputs from the inference script, you can increase beam_width and num_translations_per_input from 10 to something like 30, or even more if you like.
If you want to do something similar to Charles the AI on Twitter, then you can just slightly modify this inference script. For example, I take this script, and then, within the while True loop, I check the database for any new social media inputs. If there are any that haven't yet been responded to, I use the model to create a response and store it to the database. Then using the Twitter/Twitch/Reddit APIs, I actually produce a response.
You will also need to "pick" a response. You could go with the first response from the chatbot, but, due to the beam search, you can see quite a few options, might as well use them! If you run inference, you will see there are many outputs:
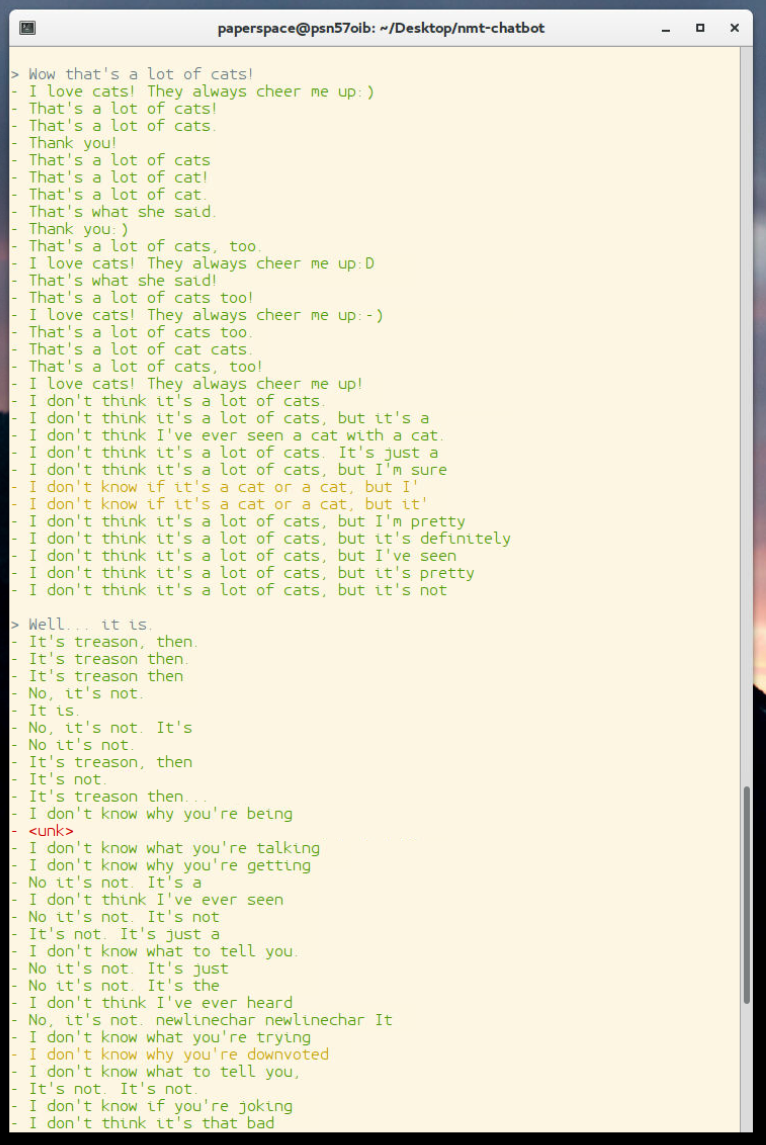
Each chatbot is likely to be different, but, as noted before, there are many output issues that we might commonly see here. For example, the <unk> token is relatively ugly and unfriendly looking, but also my bot likes to often repeat the questions or not finish thoughts, so we might want to use a little natural language processing to attempt to pick the best answer that we can. At the time of my writing this, I have written a scoring script to sit on top of the scoring that Daniel has done, you can find it in the sentdex_lab directory. Basically, all of the files in here need to sit in the root project directory if you want to use them. If you do though, you can tweak scoring.py to your liking. Then, you can run modded-inference.py, and get the singular highest-scoring result, for example:
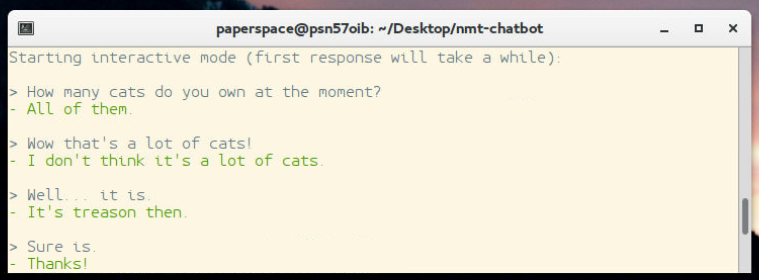
Okay, well, that's enough for now. At this point, you have a lot of tweaking to do, and playing around. I am still messing around with various model sizes, and hope to play more with better ways to tokenize the data, in order to have a much larger overall vocabulary in terms of output possibilities. I am also interested in taking a general model, and then, at the end, passing through mainly sarcastic data, to see if I can use transfer learning to make a "Charles with an attitude" type of bot... but we'll see.
-
Creating a Chatbot with Deep Learning, Python, and TensorFlow Part 1
-
Chat Data Structure - Creating a Chatbot with Deep Learning, Python, and TensorFlow Part 2
-
Buffering Data - Creating a Chatbot with Deep Learning, Python, and TensorFlow Part 3
-
Insert Logic - Creating a Chatbot with Deep Learning, Python, and TensorFlow Part 4
-
Building Database - Creating a Chatbot with Deep Learning, Python, and TensorFlow Part 5
-
Training Dataset - Creating a Chatbot with Deep Learning, Python, and TensorFlow Part 6
-
Training a Model - Creating a Chatbot with Deep Learning, Python, and TensorFlow Part 7
-
Exploring concepts and parameters of our NMT Model - Creating a Chatbot with Deep Learning, Python, and TensorFlow Part 8
-
Interacting with our Chatbot - Creating a Chatbot with Deep Learning, Python, and TensorFlow Part 9
