Exploring concepts and parameters of our NMT Model - Creating a Chatbot with Deep Learning, Python, and TensorFlow Part 8
Welcome to part 8 of the chatbot with Python and TensorFlow tutorial series. Here, we're going to discuss our model.
The main initial difference between these, to you, is no more bucketing, padding and the addition of attention mechanisms. Let's briefly talk about these things before we get started. First, if you're familiar with neural networks, consider a task like sequence to sequence, where the sequences aren't exactly the same length. We can consider this within the realm of chatbots, but other realms as well. In the case of a chatbot, one word statements could yield 20-word responses, and long statements could return single-word responses, and, each input is going to vary from the last in terms of characters, words, and more. Words themselves will be assigned either arbitrary or meaningful ids (via word vectors), but how do we handle the variable lengths? One answer is to just make all strings of words 50 words long (for example). Then, when statements are 35 words long, we could just pad the other 15. Any data longer than 50 words, we can either not use for training, or truncate.
Unfortunately, this can make training hard, especially for shorter responses which might be the most common, and most of the words/tokens will just be padding. The original seq2seq (English to French) example used bucketing to solve for this, and trained with 4 buckets. 5-10, 10-15, 20-25, and 40-50, and we'd wind up putting the training data into the smallest bucket that would fit both input and output, but this isn't quite ideal.
Then we have the NMT code that works with variable inputs, no bucketing or padding! Next, this code also contains support for attention mechanisms, which are an attempt at adding longer-term memory to recurrent neural networks. Finally, we'll also be making use of bidirectional recurrent neural networks (BRNN). Let's talk about these things.
In general, an LSTM can remember decently sequences of tokens up to 10-20 in length fairly well. After this point, however, performance drops and the network forgets the initial tokens to make room for the new ones. In our case, tokens are words, so a basic LSTM should be capable of learning 10-20 word-length sentences, but, as we go longer than this, chances are, the output is going to not be as good. Attention mechanisms come in to seek to give longer "attention spans," which help a network to reach more like 30,40, or even 80 words, for example. Imagine how hard it would be for you if you could only process and respond to other people in 3-10 words at a time, where at the 10-words mark you were getting pretty sloppy as it is. Heck, in that previous sentence, you only got to Imagine how hard it would be for you if you...before you needed to begin at least building your response at 10 words. Slide it a bit, and you get: hard it would be for you if you could only, again, this isn't really meaningful, and would make a good response pretty hard. Even if you do get to a point where you know you need to imagine something... imagine what? You have to wait and see the future elements to know what you're meant to imagine...but, by the time we get to those future elements, oh dear, we've long since passed the part where we're meant to imagine what it'd be like. This is where Bidirectional Recurrent Neural Networks (BRNN) come in.
In many sequence-to-sequence tasks, like with language translation, we can do pretty well by converting words in place, and learning simple patterns about grammar, since many languages are syntactically similar. With natural language and communication, along with some forms of translation like English to Japanese, there's more of an importance in context, flow...etc. There's just so much more going on. The bidirectional recurrent neural network (BRNN) assumes that data both now, in the past, and in the future is important in an input sequence. The "bidirectional" part of bidirectional recurrent neural network (BRNN) is pretty well descriptive. The input sequence goes both ways. One goes forward, and the other goes in reverse. To illustrate this:
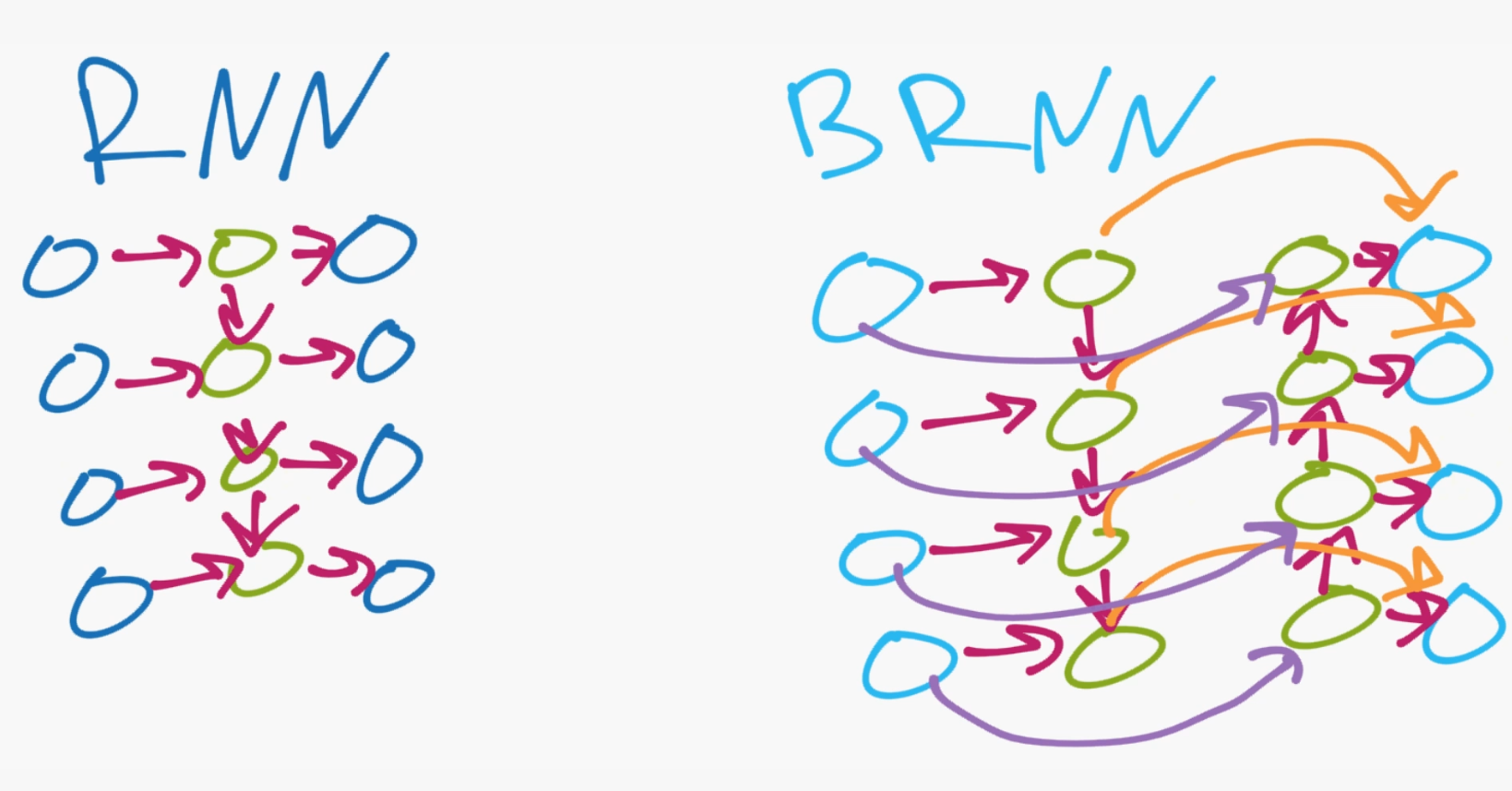
On a simple RNN, you have your input layer, your output layer, and then we'll just have one hidden layer. Then your connections go from the input layer to the hidden layer, where each node in the hidden layer also passes down to the next hidden layer node, which is how we get our "temporal," and not-so-static characteristics from recurrent neural networks, as the previous inputs are allowed to carry forward and down the hidden layer. On a BRNN, instead, your hidden layer consists of nodes going in opposite directions, so you'll have input and output layers, then you'll have your hidden layer(s). Unlike a basic RNN, however, the hidden layer passes data both up and down (or forward and backwards, depending on who is drawing the picture), which gives the network the ability to understand what's going on based on both what's happened historically, but also with what comes in the future part of the sequence that we pass.
The next addition to our network is an attention mechanism, since, despite passing data forward and backwards, our network is not good at remembering longer sequences at a time (3-10 tokens at a time max). If you're tokenizing words, which we are, that means 3-10 words at a time maximum, but this is even more problematic for character-level models, where the most you can remember is more like 3-10 characters. But, if you do a character model, you're vocab numbers can be far lower.
With attention mechanisms, we can go out to 30, 40, 80+ tokens in sequence. Here's an image depicting BLEU over the course of tokens with and without attention mechanisms:
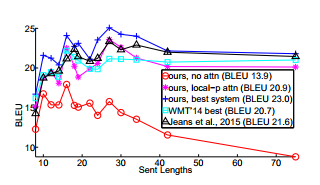
BLEU stands for "bilingual evaluation understudy," and it's probably our best way to determine the overall effectiveness of a translation algorithm. It's important to note, however, that BLEU is going to be relative to the sequences that we're translating. For example, it's likely we could achieve a far greater English to French BLEU score than English to Japanese, or even German, or any language where there really might not be any direct translation for many words, thoughts, or phrases. In our case, we're translating sequences to sequences where both sequences are English, so should we see a REALLY high BLEU? Well, probably not. With language translations, there's often an "exact" or at least a few "perfect matches" for an input (again, there are going to be some things that don't translate perfectly, but this wont be the majority). With conversational data though, is there really ever an "exact" answer to some statement? Absolutely not. We should expect to see BLEU slowly rising over time, but don't expect to see a BLEU score that is anything similar to language translation tasks.
Not only do attention mechanisms help us to go out to longer sequences, they also improve the shorter term. Attention mechanisms also allow for far more complex learning than we what need for a chatbot. The main driver for them seemed to be more for language, where it's relatively easy to translate between English and French, but the structure of a language like Japanese requires, literally, far more attention. You might really need to look at the end of the 100-word Japanese sentences to discern what the first English word should be, or visa versa. With our Chatbot, we face similar concerns. We're not translating word-for-word, for noun phrase-to-noun phrase. Instead, the end of the input sequence can and usually will completely determine what the output sequence should be. I may dive deeper into attention mechanisms later, but, for now, that's enough for a general idea.
Aside from BLEU, you will also see Perplexity, often in the short-hand "PPL." Perplexity is another decent measurement for a models effectiveness. Unlike BLEU, the lower the better, as it's a probability distribution of how effective your model is at predicting an output from a sample. Again, with language translation.
With BLEU and PPL, with translation, you probably can usually just train a model so long as BLEU is rising and PPL is falling. With a chatbot, however, where there never actually is, or never should be, a "correct" answer, I would warn against continuing to train so long as BLEU and PPL rises, since this is likely to produce more robotic-like responses, rather than highly variant ones. There will be other ways for us to combat this too that we can address later.
I hope this isn't your very first machine learning tutorial, but, if it is, you should also know what loss is. Basically loss a measure of how far "off" your output layer of the neural network was compared to the sample data. The lower the loss, the better.
The final concept that I want to mention is Beam Search. Using this, we can check out a collection of the top-translations from our model, rather than just the top one and not even considering the others. Doing this causes longer translation times, but is a definite must-have for a translation model in my opinion, since, as we'll find, our model is still highly likely to produce outputs that we don't desire, but training these outputs out might cause overfitment elsewhere. Allowing for multiple translations will help in both training and production.
Alright, in the next tutorial, we'll talk about how you can begin to interact with your chatbot.
-
Creating a Chatbot with Deep Learning, Python, and TensorFlow Part 1
-
Chat Data Structure - Creating a Chatbot with Deep Learning, Python, and TensorFlow Part 2
-
Buffering Data - Creating a Chatbot with Deep Learning, Python, and TensorFlow Part 3
-
Insert Logic - Creating a Chatbot with Deep Learning, Python, and TensorFlow Part 4
-
Building Database - Creating a Chatbot with Deep Learning, Python, and TensorFlow Part 5
-
Training Dataset - Creating a Chatbot with Deep Learning, Python, and TensorFlow Part 6
-
Training a Model - Creating a Chatbot with Deep Learning, Python, and TensorFlow Part 7
-
Exploring concepts and parameters of our NMT Model - Creating a Chatbot with Deep Learning, Python, and TensorFlow Part 8
-
Interacting with our Chatbot - Creating a Chatbot with Deep Learning, Python, and TensorFlow Part 9
