Reinforcement Learning in Python with Stable Baselines 3
Working with Custom Environments
Welcome to part 4 of the reinforcement learning with Stable Baselines 3 tutorials. In the previous tutorial, we showed how to use your own custom environment with stable baselines 3, and we found that we weren't able to get our agent to learn anything significant out of the gate.

While the agent did definitely learn to stay alive for much longer than random, we were certainly not getting any apples. Why might this be?
Unless an agent just happens to get an apple, it would never learn that it is rewarding, plus getting an apple is about as rewarding as simply not dying. How might we encourage getting the apple? One quick idea that comes to mind is to punish the agent by the euclidean distance it is from the apple. The agent would hopefully learn to get closer and closer to the apple in this case. We can achieve this by adding a euclidean distance variable and then subtracting that distance from the reward:
euclidean_dist_to_apple = np.linalg.norm(np.array(self.snake_head) - np.array(self.apple_position)) self.total_reward = len(self.snake_position) - 3 - euclidean_dist_to_apple
I will call this new env snakeenvp4.py just to keep things organized. Let's try training this one, by simply modifying the training script snakelearn.py environment import:
from snakeenvp4 import SnekEnv
Training this starts off okay, but after some time, all we get is a black screen and output like:
--------------------------------- | rollout/ | | | ep_len_mean | 1 | | ep_rew_mean | -10 | | time/ | | | fps | 693 | | iterations | 1 | | time_elapsed | 121 | | total_timesteps | 83968 | ---------------------------------
What happened?
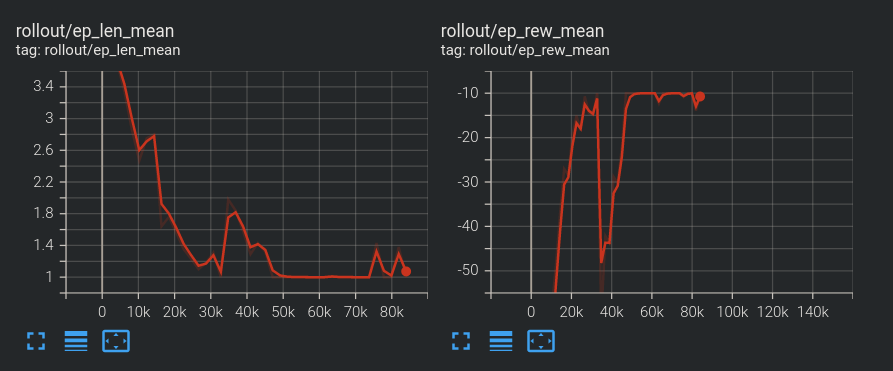
Quite simply, this agent learned that living is very painful and the quickest way to the highest reward is to go ahead and stop living. You can see that reward was typically a very large negative and then it rises as episode length decreases up to the point of -10 and it just holds there, so the agent was just simply spawning and running into itself immediately to end the game. This is a good example of how things can go awry with what we think might be a good reward, but it turns out to be no good.
To fix this, we can instead just make an offset for the euclidean distance. I propose something like maybe 250, since our game size is 500x500. When we do this, I can envision the snake learning to just circle the apple, instead of eating it. The new reward function I propose to start is:
self.total_reward = (250 - euclidean_dist_to_apple)
But then, we do want a short term reward for eating an apple too. It needs to be greater than 250 for sure, but also enough incentive for the apple to move to a new spot, so maybe 1,000 or 5,000. I really don't know. Something significant for sure. We have to consider how many steps will it take to get to the new/next apple, and would it wind up being more advantageous for the agent to just do circles around the apple for a constant ~200-250 reward. In the code where we catch if we ate the apple and lengthen the snake, I'll add a new variable, apple_reward:
apple_reward = 0 # Increase Snake length on eating apple if self.snake_head == self.apple_position: self.apple_position, self.score = collision_with_apple(self.apple_position, self.score) self.snake_position.insert(0,list(self.snake_head)) apple_reward = 10000
Then, we'll add this apple_reward to the temp reward:
self.total_reward = (250 - euclidean_dist_to_apple) + apple_reward
Then, do we really want the rewards to be deltas to what they were before? I don't think so. I think we want to make them per step, so the reward we return from the step method should be the self.total_reward
Finally, our current total reward scale is going to be too massive, we should really scale it down, I propose for now that we divide it by 100.
self.total_reward = ((250 - euclidean_dist_to_apple) + apple_reward)/100

Full code for this:
# our environement here is adapted from: https://github.com/TheAILearner/Snake-Game-using-OpenCV-Python/blob/master/snake_game_using_opencv.ipynb
import gym
from gym import spaces
import numpy as np
import cv2
import random
import time
from collections import deque
SNAKE_LEN_GOAL = 30
def collision_with_apple(apple_position, score):
apple_position = [random.randrange(1,50)*10,random.randrange(1,50)*10]
score += 1
return apple_position, score
def collision_with_boundaries(snake_head):
if snake_head[0]>=500 or snake_head[0]<0 or snake_head[1]>=500 or snake_head[1]<0 :
return 1
else:
return 0
def collision_with_self(snake_position):
snake_head = snake_position[0]
if snake_head in snake_position[1:]:
return 1
else:
return 0
class SnekEnv(gym.Env):
def __init__(self):
super(SnekEnv, self).__init__()
# Define action and observation space
# They must be gym.spaces objects
# Example when using discrete actions:
self.action_space = spaces.Discrete(4)
# Example for using image as input (channel-first; channel-last also works):
self.observation_space = spaces.Box(low=-500, high=500,
shape=(5+SNAKE_LEN_GOAL,), dtype=np.float32)
def step(self, action):
self.prev_actions.append(action)
cv2.imshow('a',self.img)
cv2.waitKey(1)
self.img = np.zeros((500,500,3),dtype='uint8')
# Display Apple
cv2.rectangle(self.img,(self.apple_position[0],self.apple_position[1]),(self.apple_position[0]+10,self.apple_position[1]+10),(0,0,255),3)
# Display Snake
for position in self.snake_position:
cv2.rectangle(self.img,(position[0],position[1]),(position[0]+10,position[1]+10),(0,255,0),3)
# Takes step after fixed time
t_end = time.time() + 0.05
k = -1
while time.time() < t_end:
if k == -1:
k = cv2.waitKey(1)
else:
continue
button_direction = action
# Change the head position based on the button direction
if button_direction == 1:
self.snake_head[0] += 10
elif button_direction == 0:
self.snake_head[0] -= 10
elif button_direction == 2:
self.snake_head[1] += 10
elif button_direction == 3:
self.snake_head[1] -= 10
apple_reward = 0
# Increase Snake length on eating apple
if self.snake_head == self.apple_position:
self.apple_position, self.score = collision_with_apple(self.apple_position, self.score)
self.snake_position.insert(0,list(self.snake_head))
apple_reward = 10000
else:
self.snake_position.insert(0,list(self.snake_head))
self.snake_position.pop()
# On collision kill the snake and print the score
if collision_with_boundaries(self.snake_head) == 1 or collision_with_self(self.snake_position) == 1:
font = cv2.FONT_HERSHEY_SIMPLEX
self.img = np.zeros((500,500,3),dtype='uint8')
cv2.putText(self.img,'Your Score is {}'.format(self.score),(140,250), font, 1,(255,255,255),2,cv2.LINE_AA)
cv2.imshow('a',self.img)
self.done = True
euclidean_dist_to_apple = np.linalg.norm(np.array(self.snake_head) - np.array(self.apple_position))
self.total_reward = ((250 - euclidean_dist_to_apple) + apple_reward)/100
print(self.total_reward)
self.reward = self.total_reward - self.prev_reward
self.prev_reward = self.total_reward
if self.done:
self.reward = -10
info = {}
head_x = self.snake_head[0]
head_y = self.snake_head[1]
snake_length = len(self.snake_position)
apple_delta_x = self.apple_position[0] - head_x
apple_delta_y = self.apple_position[1] - head_y
# create observation:
observation = [head_x, head_y, apple_delta_x, apple_delta_y, snake_length] + list(self.prev_actions)
observation = np.array(observation)
return observation, self.total_reward, self.done, info
def reset(self):
self.img = np.zeros((500,500,3),dtype='uint8')
# Initial Snake and Apple position
self.snake_position = [[250,250],[240,250],[230,250]]
self.apple_position = [random.randrange(1,50)*10,random.randrange(1,50)*10]
self.score = 0
self.prev_button_direction = 1
self.button_direction = 1
self.snake_head = [250,250]
self.prev_reward = 0
self.done = False
head_x = self.snake_head[0]
head_y = self.snake_head[1]
snake_length = len(self.snake_position)
apple_delta_x = self.apple_position[0] - head_x
apple_delta_y = self.apple_position[1] - head_y
self.prev_actions = deque(maxlen = SNAKE_LEN_GOAL) # however long we aspire the snake to be
for i in range(SNAKE_LEN_GOAL):
self.prev_actions.append(-1) # to create history
# create observation:
observation = [head_x, head_y, apple_delta_x, apple_delta_y, snake_length] + list(self.prev_actions)
observation = np.array(observation)
return observation
